docs
分布式文件系统测试方法与测试工具: https://zhuanlan.zhihu.com/p/36415684 https://blog.csdn.net/yanbin125789/article/details/128275524
ZNS设备模拟
ZNS设备模拟
1.Setting-up a Zoned Storage Compatible Linux System
Overview
- A compatible Linux distribution with the right kernel version
- Support for zoned block devices
- Necessary system utilities
配置ZNS需要正确的内核版本以能够支持相应的版本,首先建立可以和zoned storage相兼容的linux system。
Linux Distribution
一些linux发行版本提供了zoned storage的支持,这些发行版本的常规安装提供了可以支持SMR硬盘和ZNS SSDs的支持。
这里采用Ubuntu 20.04跑在VMWare上的虚拟机作为安装的linux system。
当然也可以用其他的版本,下载的发行版本需要满足两个条件:
- The kernel version must be 4.10.0 or higher.
- The kernel configuration option CONFIG_BLK_DEV_ZONED must be enabled.
install Fedora can be found here.
1.测试内核版本:
uname -r

2.用以下两条命令来检测是否支持Zoned Block Device:
cat /boot/config-`uname -r` | grep CONFIG_BLK_DEV_ZONED
cat /lib/modules/`uname -r`/config | grep CONFIG_BLK_DEV_ZONED

3.检查系统配置
write ordering control
linux内核并不保证命令到达设备的顺序,这意味到达磁盘的写命令顺序可能会打乱,因此可能造成写错误。为了避免这个错误,"zone write lock mechanism" 用来顺序化这些操作。
查看block I/O调度器:
# cat /sys/block/sdb/queue/scheduler
[none] mq-deadline kyber bfq

如果不是mq-deadline的调度器,需要切换成mq-deadline的调度器:
# echo mq-deadline > /sys/block/sdb/queue/scheduler
# cat sys/block/sdb/queue/scheduler
[mq-deadline] kyber bfq none
System Utilities
按照说明里边我只找到了lsblk指令,其他的诸如没找到sg3_utils,lsscsi等。
不过在ubuntu里边可以用zbd这个指令来和blkzone起到类似的效果,这个命令是用来看zone的信息的。
安装libzbd的过程如下:
首先libzbd需要下面的package进行编译:
# 如果想要有图形化界面的gzbd和gzbd-viewer的话 还需要首先安装libgtk-3-dev这个包
# sudo apt install libgtk-3-dev
# apt-get install autoconf
# apt-get install autoconf-archive
# apt-get install automake
# apt-get install libtool
# apt-get install m4
同时系统需要有blkzoned.h,头文件在/usr/include/linux里边可以找一下:
sudo ls /usr/include/linux/ | grep blkzoned
然后把libzbd的包下下来,在已经下载的文件夹里面编译一遍:
git clone https://github.com/westerndigitalcorporation/libzbd.git
sh ./autogen.sh
./configure
make
默认下载在/usr.lib或者/usr/lib64下。
不过这个在Ubuntu22.04里边有个zbd-utils可以直接用apt下载。
2.Zoned Block Device模拟方法
最简单的方法是创建null block的方式来模拟block device
简单创建方法
创建一个null block块:
modprobe null_blk nr_devices=1 zoned=1
nr_devices=1表示仅创建一个设备;zoned=1表示创建的所有设备都是分区设备。
可以用lsblk来查看一下信息:
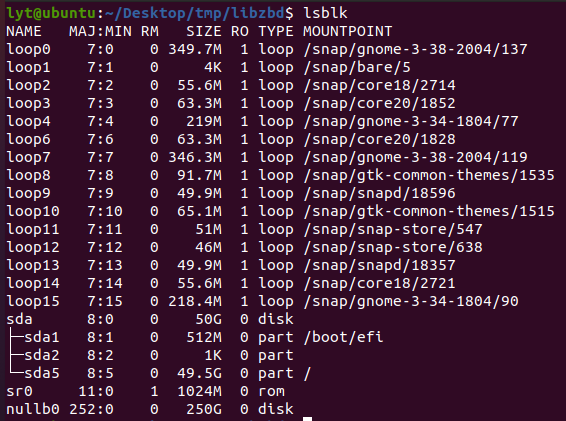
可以看到我们创建了一个nullb0的设备。
还可以用zbd来查看分区块设备的信息:
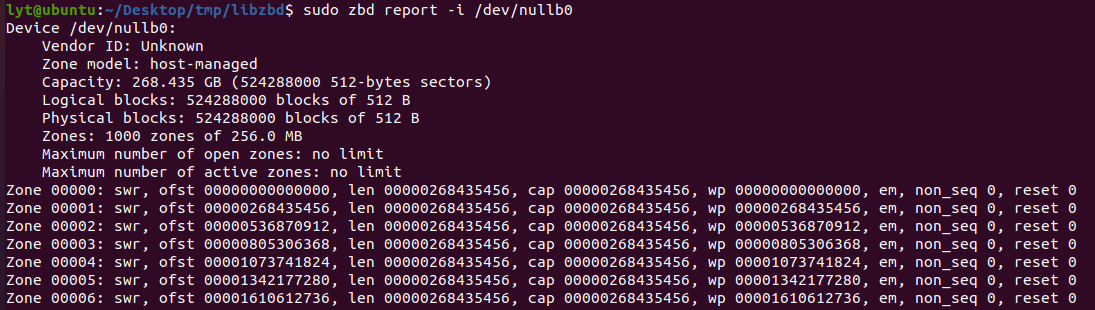
删除一个由modprobe创建(且不由configfs创建)的模拟设备可用以下方法删除:
rmmod null_blk
高级创建方法
# modprobe null_blk nr_devices=1 \
zoned=1 \
zone_nr_conv=4 \
zone_size=64 \
nr_devices=1表示仅创建一个设备;
zoned=1表示创建的所有设备都是分区设备;
zone_nr_conv=4表示传统的Zone个数为4;
zone_size=64表示每个Zone有64MB。
configfs接口为创建模拟分区块设备提供了强大的手段。configfs可供修改的参数如下:
# cat /sys/kernel/config/nullb/features
memory_backed,discard,bandwidth,cache,badblocks,zoned,zone_size,zone_capacity,zone_nr_conv,zone_max_open,zone_max_active,blocksize,max_sectors,virt_boundary
需要注意的是不同内核版本可修改的参数是不一样的:
| kernel | feature |
|---|---|
| 4.10.0 | zoned |
| 4.10.0 | chunk_sectors |
| 4.20.0 | nr_zones |
| 5.8.0 | zone_append_max_bytes |
| 5.9.0 | max_open_zones |
| 5.9.0 | max_active_zones |
configfs接口可以用来用脚本创建具有不同zone配置的模拟zone块设备。
创建内容如下的脚本:
#!/bin/bash
if [ $# != 4 ]; then
echo "Usage: $0 <sect size (B)> <zone size (MB)> <nr conv zones> <nr seq zones>"
exit 1
fi
scriptdir=$(cd $(dirname "$0") && pwd)
modprobe null_blk nr_devices=0 || return $?
function create_zoned_nullb()
{
local nid=0
local bs=$1
local zs=$2
local nr_conv=$3
local nr_seq=$4
cap=$(( zs * (nr_conv + nr_seq) ))
while [ 1 ]; do
if [ ! -b "/dev/nullb$nid" ]; then
break
fi
nid=$(( nid + 1 ))
done
dev="/sys/kernel/config/nullb/nullb$nid"
mkdir "$dev"
echo $bs > "$dev"/blocksize
echo 0 > "$dev"/completion_nsec
echo 0 > "$dev"/irqmode
echo 2 > "$dev"/queue_mode
echo 1024 > "$dev"/hw_queue_depth
echo 1 > "$dev"/memory_backed
echo 1 > "$dev"/zoned
echo $cap > "$dev"/size
echo $zs > "$dev"/zone_size
echo $nr_conv > "$dev"/zone_nr_conv
echo 1 > "$dev"/power
echo mq-deadline > /sys/block/nullb$nid/queue/scheduler
echo "$nid"
}
nulldev=$(create_zoned_nullb $1 $2 $3 $4)
echo "Created /dev/nullb$nulldev"
运行脚本,脚本的四个参数分别为:
- 模拟设备的扇区大小(bytes)
- 模拟设备的zone大小(MiB)
- 传统zone个数
- 有顺序写限制的zone个数
运行结果如下:
# ./nullblk-zoned.sh 4096 64 4 8
Created /dev/nullb0
# zbd report -i /dev/nullb0
Device /dev/nullb0:
Vendor ID: Unknown
Zone model: host-managed
Capacity: 0.805 GB (1572864 512-bytes sectors)
Logical blocks: 196608 blocks of 4096 B
Physical blocks: 196608 blocks of 4096 B
Zones: 12 zones of 64.0 MB
Maximum number of open zones: no limit
Maximum number of active zones: no limit
Zone 00000: cnv, ofst 00000000000000, len 00000067108864, cap 00000067108864
Zone 00001: cnv, ofst 00000067108864, len 00000067108864, cap 00000067108864
Zone 00002: cnv, ofst 00000134217728, len 00000067108864, cap 00000067108864
Zone 00003: cnv, ofst 00000201326592, len 00000067108864, cap 00000067108864
Zone 00004: swr, ofst 00000268435456, len 00000067108864, cap 00000067108864, wp 00000268435456, em, non_seq 0, reset 0
Zone 00005: swr, ofst 00000335544320, len 00000067108864, cap 00000067108864, wp 00000335544320, em, non_seq 0, reset 0
Zone 00006: swr, ofst 00000402653184, len 00000067108864, cap 00000067108864, wp 00000402653184, em, non_seq 0, reset 0
Zone 00007: swr, ofst 00000469762048, len 00000067108864, cap 00000067108864, wp 00000469762048, em, non_seq 0, reset 0
Zone 00008: swr, ofst 00000536870912, len 00000067108864, cap 00000067108864, wp 00000536870912, em, non_seq 0, reset 0
Zone 00009: swr, ofst 00000603979776, len 00000067108864, cap 00000067108864, wp 00000603979776, em, non_seq 0, reset 0
Zone 00010: swr, ofst 00000671088640, len 00000067108864, cap 00000067108864, wp 00000671088640, em, non_seq 0, reset 0
Zone 00011: swr, ofst 00000738197504, len 00000067108864, cap 00000067108864, wp 00000738197504, em, non_seq 0, reset 0
用脚本创建的分区块设备的删除也需要使用脚本:
#!/bin/bash
if [ $# != 1 ]; then
echo "Usage: $0 <nullb ID>"
exit 1
fi
nid=$1
if [ ! -b "/dev/nullb$nid" ]; then
echo "/dev/nullb$nid: No such device"
exit 1
fi
echo 0 > /sys/kernel/config/nullb/nullb$nid/power
rmdir /sys/kernel/config/nullb/nullb$nid
echo "Destroyed /dev/nullb$nid"
运行结果如下:
# ./nullblk-del.sh 0
Destroyed /dev/nullb0
3.在ZONED BLOCK DEVICE上模拟ZenFS
好了,现在我们可以来基于zbd建立zenfs的文件系统。
记得要把之前的libzbd安装了。
首先建立一个null_blk的zone device block,利用如下脚本:
#!/bin/bash
if [ $# != 7 ]; then
echo "Usage: $0 <sect size (B)> <zone size (MB)> <zone capacity (MB)> <nr conv zones> <nr seq zones> <max active zones> <max open zones>"
exit 1
fi
scriptdir="$(cd "$(dirname "$0")" && pwd)"
modprobe null_blk nr_devices=0 || return $?
function create_zoned_nullb()
{
local nid=0
local bs=$1
local zs=$2
local zc=$3
local nr_conv=$4
local nr_seq=$5
local max_active_zones=$6
local max_open_zones=$7
cap=$(( zs * (nr_conv + nr_seq) ))
while [ 1 ]; do
if [ ! -b "/dev/nullb$nid" ]; then
break
fi
nid=$(( nid + 1 ))
done
dev="/sys/kernel/config/nullb/nullb$nid"
mkdir "$dev"
echo $bs > "$dev"/blocksize
echo 0 > "$dev"/completion_nsec
echo 0 > "$dev"/irqmode
echo 2 > "$dev"/queue_mode
echo 1024 > "$dev"/hw_queue_depth
echo 1 > "$dev"/memory_backed
echo 1 > "$dev"/zoned
echo $cap > "$dev"/size
echo $zs > "$dev"/zone_size
echo $zc > "$dev"/zone_capacity
echo $nr_conv > "$dev"/zone_nr_conv
echo $max_active_zones > "$dev"/zone_max_active
echo $max_open_zones > "$dev"/zone_max_open
echo 1 > "$dev"/power
echo mq-deadline > /sys/block/nullb$nid/queue/scheduler
echo "$nid"
}
nulldev=$(create_zoned_nullb $1 $2 $3 $4 $5 $6 $7)
echo "Created /dev/nullb$nulldev"
然后设置对应的参数
chmod +x nullblk-zoned.sh
sudo ./nullblk-zoned.sh 512 128 124 0 32 12 12
这样一个zbd就在建立好了,可以用lsblk命令查看一下,现在应该有了一个叫做/dev/nullb0的设备,不过是空的,再用gzbd-viewer查看一下这个设备:
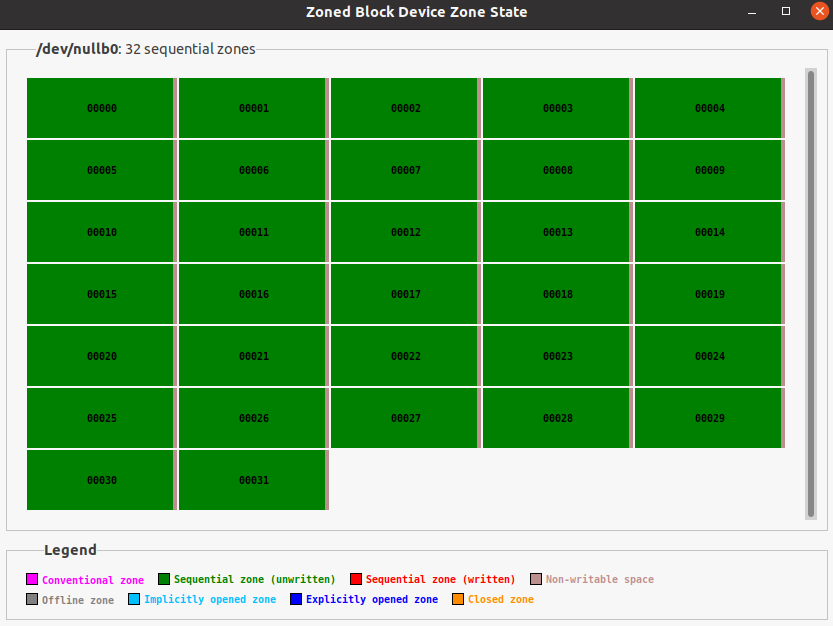
之后我们可以利用fio向里面写入数据,首先下载fio:
git clone https://github.com/axboe/fio.git
cd fio
./configure
make -j$(nproc --all)
sudo make install
再往里面写入数据:
sudo fio --name=test --filename=/dev/nullb0 --zonemode=zbd --direct=1 --runtime=5 --ioengine=io_uring --hipri --rw=randwrite --iodepth=1 --bs=16K --max_open_zones=12
可以用gzbd-viewer查看zbd的情况:
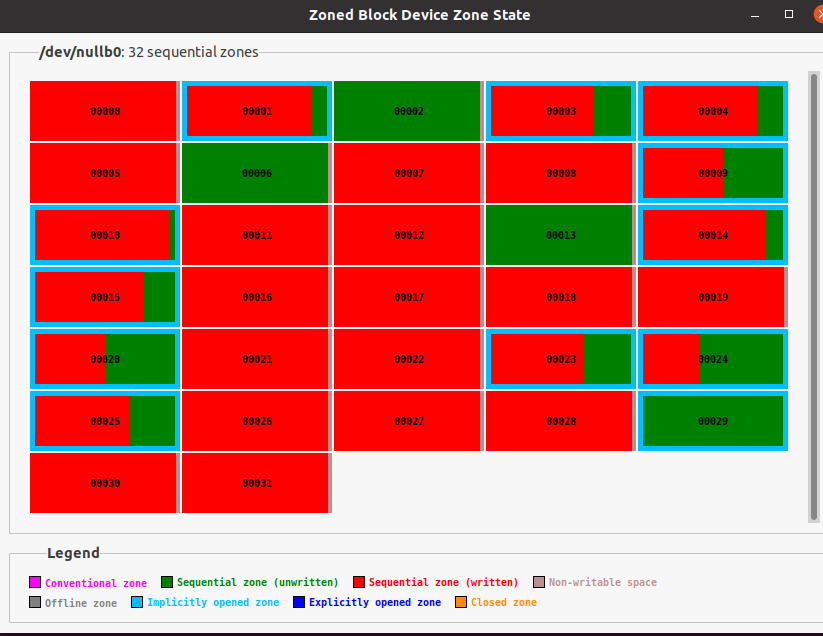
最后我们利用脚本在nullb0上创建一个zenfs文件系统:
#!/bin/sh -ex
DEV=nullb0
FUZZ=5
ZONE_SZ_SECS=$(cat /sys/class/block/$DEV/queue/chunk_sectors)
ZONE_CAP=$((ZONE_SZ_SECS * 512))
BASE_FZ=$(($ZONE_CAP * (100 - $FUZZ) / 100))
WB_SIZE=$(($BASE_FZ * 2))
TARGET_FZ_BASE=$WB_SIZE
TARGET_FILE_SIZE_MULTIPLIER=2
MAX_BYTES_FOR_LEVEL_BASE=$((2 * $TARGET_FZ_BASE))
MAX_BACKGROUND_JOBS=8
MAX_BACKGROUND_COMPACTIONS=8
OPEN_FILES=16
echo deadline > /sys/class/block/$DEV/queue/scheduler
./plugin/zenfs/util/zenfs mkfs --zbd=$DEV --aux_path=/tmp/zenfs_$DEV --finish_threshold=0 --force
./db_bench --fs_uri=zenfs://dev:$DEV --key_size=16 --value_size=800 --target_file_size_base=$TARGET_FZ_BASE \
--write_buffer_size=$WB_SIZE --max_bytes_for_level_base=$MAX_BYTES_FOR_LEVEL_BASE \
--max_bytes_for_level_multiplier=4 --use_direct_io_for_flush_and_compaction \
--num=1500000 --benchmarks=fillrandom,overwrite --max_background_jobs=$MAX_BACKGROUND_JOBS \
--max_background_compactions=$MAX_BACKGROUND_COMPACTIONS --open_files=$OPEN_FILES
用gzbd-viewer看一下写入数据:

在db_bench上进行测试:
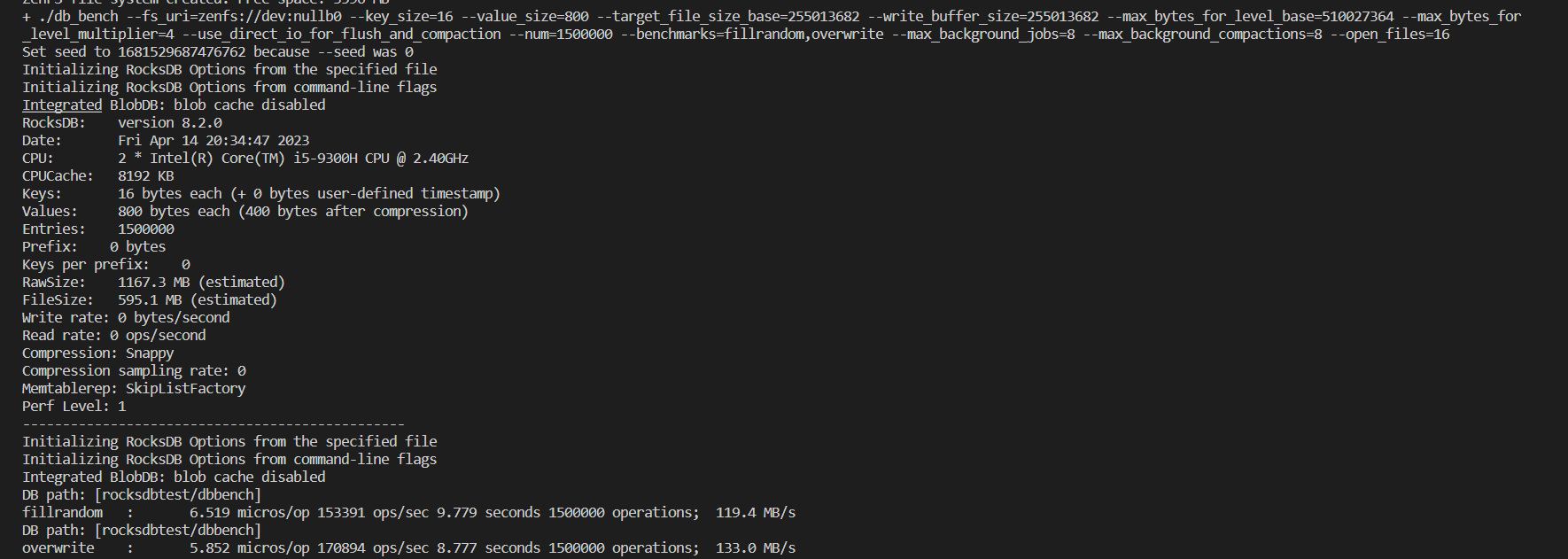
在zenfs的tests目录中可以对文件系统进行测试。
Null Block Device
nullblk 即 Null block device driver,空块设备(/dev/nullb*),用于对各种块层实现进行基准测试。它模拟 X GB 大小的块设备。它不执行任何读/写操作,只是在请求队列中将它们标记为完成,用于对各种 block-layer 实现进行基准测试。
nullblk 已经被合入 Linux Kernel 主线,具体用法可以参考内核文档。
TODO: nullblk 的工作原理分析
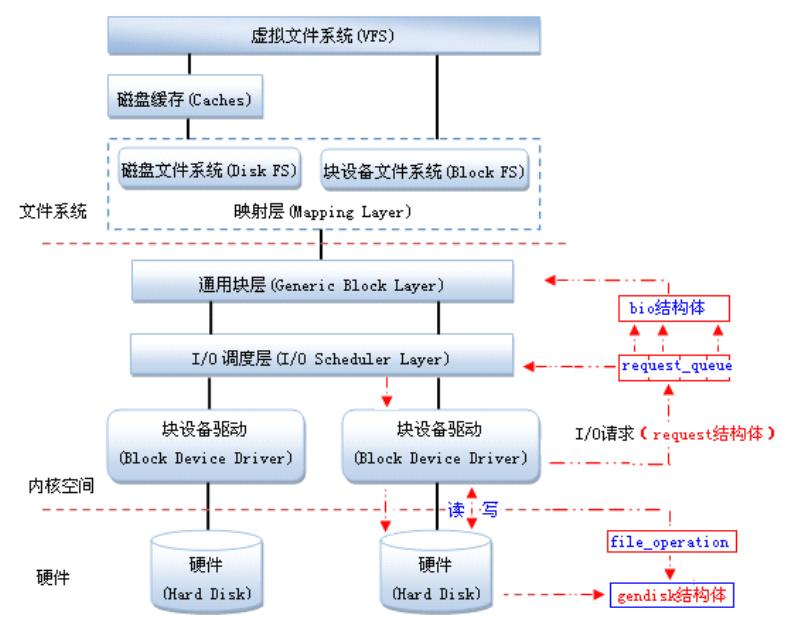
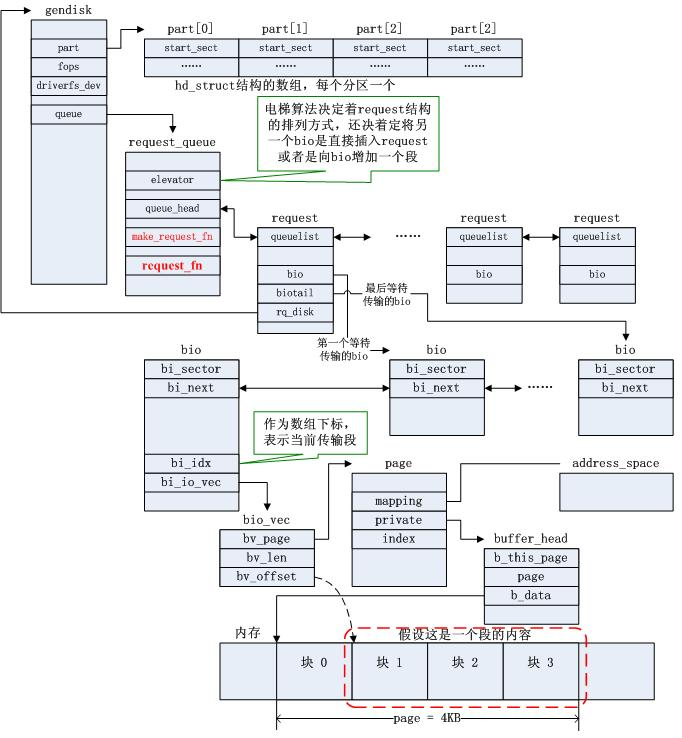
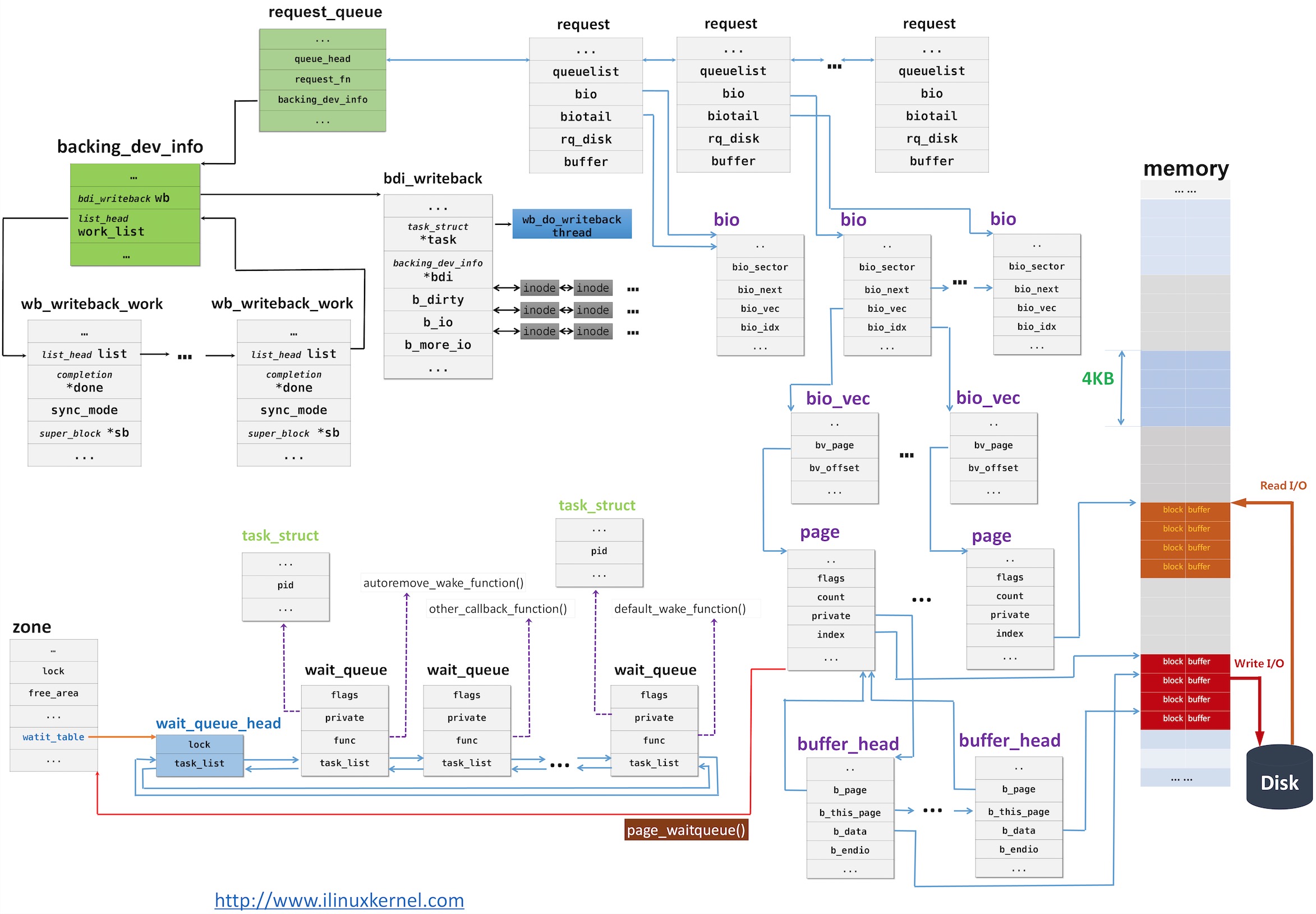
https://blog.csdn.net/weixin_34216107/article/details/92562214
Null block device driver
Null block device driver
==================================
I. Overview
The null block device (/dev/nullb*) is used for benchmarking the various
block-layer implementations. It emulates a block device of X gigabytes in size.
The following instances are possible:
Single-queue block-layer
- Request-based.
- Single submission queue per device.
- Implements IO scheduling algorithms (CFQ, Deadline, noop).
Multi-queue block-layer
- Request-based.
- Configurable submission queues per device.
No block-layer (Known as bio-based)
- Bio-based. IO requests are submitted directly to the device driver.
- Directly accepts bio data structure and returns them.
All of them have a completion queue for each core in the system.
II. Module parameters applicable for all instances:
queue_mode=[0-2]: Default: 2-Multi-queue
Selects which block-layer the module should instantiate with.
0: Bio-based.
1: Single-queue.
2: Multi-queue.
home_node=[0--nr_nodes]: Default: NUMA_NO_NODE
Selects what CPU node the data structures are allocated from.
gb=[Size in GB]: Default: 250GB
The size of the device reported to the system.
bs=[Block size (in bytes)]: Default: 512 bytes
The block size reported to the system.
nr_devices=[Number of devices]: Default: 1
Number of block devices instantiated. They are instantiated as /dev/nullb0,
etc.
irqmode=[0-2]: Default: 1-Soft-irq
The completion mode used for completing IOs to the block-layer.
0: None.
1: Soft-irq. Uses IPI to complete IOs across CPU nodes. Simulates the overhead
when IOs are issued from another CPU node than the home the device is
connected to.
2: Timer: Waits a specific period (completion_nsec) for each IO before
completion.
completion_nsec=[ns]: Default: 10,000ns
Combined with irqmode=2 (timer). The time each completion event must wait.
submit_queues=[1..nr_cpus]:
The number of submission queues attached to the device driver. If unset, it
defaults to 1. For multi-queue, it is ignored when use_per_node_hctx module
parameter is 1.
hw_queue_depth=[0..qdepth]: Default: 64
The hardware queue depth of the device.
III: Multi-queue specific parameters
use_per_node_hctx=[0/1]: Default: 0
0: The number of submit queues are set to the value of the submit_queues
parameter.
1: The multi-queue block layer is instantiated with a hardware dispatch
queue for each CPU node in the system.
no_sched=[0/1]: Default: 0
0: nullb* use default blk-mq io scheduler.
1: nullb* doesn't use io scheduler.
blocking=[0/1]: Default: 0
0: Register as a non-blocking blk-mq driver device.
1: Register as a blocking blk-mq driver device, nullblk will set
the BLK_MQ_F_BLOCKING flag, indicating that it sometimes/always
needs to block in its ->queue_rq() function.
shared_tags=[0/1]: Default: 0
0: Tag set is not shared.
1: Tag set shared between devices for blk-mq. Only makes sense with
nr_devices > 1, otherwise there's no tag set to share.
zoned=[0/1]: Default: 0
0: Block device is exposed as a random-access block device.
1: Block device is exposed as a host-managed zoned block device. Requires
CONFIG_BLK_DEV_ZONED.
zone_size=[MB]: Default: 256
Per zone size when exposed as a zoned block device. Must be a power of two.
zone_nr_conv=[nr_conv]: Default: 0
The number of conventional zones to create when block device is zoned. If
zone_nr_conv >= nr_zones, it will be reduced to nr_zones - 1.
Q:nullblk 是什么?
A:nullblk 是 Linux 内核中的一个模块,它是块设备的一种。它可以用于模拟无任何实际存储介质的块设备。通过使用 nullblk,开发人员可以测试块设备的各种功能,而无需实际硬件。这对于开发和测试块设备驱动程序非常有用。
Q:nullblk 是如何工作的?
A:nullblk 模块会创建一个虚拟的块设备,这个设备不会存储任何数据,但是它会像一个真实的块设备一样响应 I/O 请求。当一个应用程序向 nullblk 发送 I/O 请求时,nullblk 会将这些请求传递给相应的块设备驱动程序。因为 nullblk 不实际存储任何数据,所以这些请求不会写入或读取任何数据,而是简单地被忽略掉。
Q:可以用什么命令加载 nullblk?
A:您可以使用以下命令加载 nullblk 模块:
modprobe null_blk
Q:可以使用什么命令卸载 nullblk?
A:您可以使用以下命令卸载 nullblk 模块:
rmmod null_blk
Q:可以用什么命令创建 nullblk 设备?
A:您可以使用以下命令创建 nullblk 设备:
modprobe null_blk nr_devices=1
此命令将创建一个名为 /dev/nullb0 的 nullblk 设备。您可以在需要使用块设备的应用程序中使用此设备。
Q:可以用什么命令查看 nullblk 设备的状态?
A:您可以使用以下命令查看 nullblk 设备的状态:
cat /sys/block/nullb0/size
此命令将输出 nullblk 设备的大小。
可以说,使用 nullblk 并不能在仿真中测量系统的整体性能,它更多的是仿真了 Linux Kernel 中外存的队列执行情况。所以,使用 nullblk 只能用于测试代码能否跑通,可能并不能测量其具体读写性能指标等。
nullblk 的使用和修改
由于 ZNS 实物申请需要一段时间,或者无法申请到,所以我们需要一个仿真环境来进行我们的开发流程。nullblk 可以仿真块设备,并可以设置为只能顺序写的模式,正好仿真 ZNS 中的硬件 Zones。
使用 nullblk
在测试中,可以方便地用脚本调用 Linux Kernel 的系统调用来创建 nullblk。在之前的文档中,我们已经获取了 nullblk-zoned.sh,执行
sudo ./nullblk-zoned.sh 4096 128 64 64
则可以创建一个 8GiB 的仿真 ZNS 磁盘。
在代码中,ZenFS 依赖 libzbd 对下层 I/O 进行控制。
调研
Flash
分类和特点
- eMMC:主要用于嵌入式系统、移动设备等场景,集成了 Flash 存储器和控制器,支持高速读写和可靠性管理,但存储密度较低。(eMMC=控制器+Nand。FTL 在控制器中。)
.png)
- NorFlash:适用于需要快速读取和低成本的应用,例如嵌入式系统、固件存储、引导程序等,读取速度较快但存储密度较低。
- NandFlash:适用于需要更高存储密度和较低成本的应用,例如移动设备、数码相机、固态硬盘等,存储密度更高,但读取速度较慢且需要进行擦除操作才能写入新的数据,寿命也相对较短,需要采用 wear leveling 和 error correction 等技术来提高寿命和可靠性。(一般厂商的 Nand Flash 不带有 FTL 层)
.png)
NAND flash和NOR flash的性能比较
flash闪存是非易失存储器,可以对称为块的存储器单元块进行擦写和再编程。任何flash器件的写入操作只能在空或已擦除的单元内进行,所以大多数情况下,在进行写入操作之前必须先执行擦除。NAND器件执行擦除操作是十分简单的,而NOR则要求在进行擦除前先要将目标块内所有的位都写为0。由于擦除NOR器件时是以64~128KB的块进行的,执行一个写入/擦除操作的时间为5s,与此相反,擦除NAND器件是以8~32KB的块进行的,执行相同的操作最多只需要4ms。执行擦除时块尺寸的不同进一步拉大了NOR和NADN之间的性能差距,统计表明,对于给定的一套写入操作(尤其是更新小文件时),更多的擦除操作必须在基于NOR的单元中进行。这样,当选择存储解决方案时,设计师必须权衡以下的各项因素。
1、NOR的读速度比NAND稍快一些。 2、NAND的写入速度比NOR快很多。 3、NAND的4ms擦除速度远比NOR的5s快。 4、大多数写入操作需要先进行擦除操作。 5、NAND的擦除单元更小,相应的擦除电路更少。
NAND flash和NOR flash的接口差别
NOR flash带有SRAM接口,有足够的地址引脚来寻址,可以很容易地存取其内部的每一个字节。 NAND器件使用复杂的I/O口来串行地存取数据,各个产品或厂商的方法可能各不相同。8个引脚用来传送控制、地址和数据信息。NAND读和写操作采用512字节的块,这一点有点像硬盘管理此类操作,很自然地,基于NAND的存储器就可以取代硬盘或其他块设备。
NAND flash和NOR flash的容量和成本
NAND flash的单元尺寸几乎是NOR器件的一半,由于生产过程更为简单,NAND结构可以在给定的模具尺寸内提供更高的容量,也就相应地降低了价格。 NOR flash占据了容量为1~16MB闪存市场的大部分,而NAND flash只是用在8~128MB的产品当中,这也说明NOR主要应用在代码存储介质中,NAND适合于数据存储,NAND在CompactFlash、Secure Digital、PC Cards和MMC存储卡市场上所占份额最大。
NAND flash和NOR flash的寿命(耐用性)
在NAND闪存中每个块的最大擦写次数是一百万次,而NOR的擦写次数是十万次。NAND存储器除了具有10比1的块擦除周期优势,典型的NAND块尺寸要比NOR器件小8倍,每个NAND存储器块在给定的时间内的删除次数要少一些。
位交换
所有flash器件都受位交换现象的困扰。在某些情况下(很少见,NAND发生的次数要比NOR多),一个比特位会发生反转或被报告反转了。一位的变化可能不很明显,但是如果发生在一个关键文件上,这个小小的故障可能导致系统停机。如果只是报告有问题,多读几次就可能解决了。当然,如果这个位真的改变了,就必须采用错误探测/错误更正(EDC/ECC)算法。位反转的问题更多见于NAND闪存,NAND的供应商建议使用NAND闪存的时候,同时使用0EDC/ECC算法。这个问题对于用NAND存储多媒体信息时倒不是致命的。当然,如果用本地存储设备来存储操作系统、配置文件或其他敏感信息时,必须使用EDC/ECC系统以确保可靠性。
坏块处理
NAND器件中的坏块是随机分布的。以前也曾有过消除坏块的努力,但发现成品率太低,代价太高,根本不划算。 NAND器件需要对介质进行初始化扫描以发现坏块,并将坏块标记为不可用。在已制成的器件中,如果通过可靠的方法不能进行这项处理,将导致高故障率。
易于使用
可以非常直接地使用基于NOR的闪存,可以像其他存储器那样连接,并可以在上面直接运行代码。 由于需要I/O接口,NAND要复杂得多。各种NAND器件的存取方法因厂家而异。在使用NAND器件时,必须先写入驱动程序,才能继续执行其他操作。向NAND器件写入信息需要相当的技巧,因为设计师绝不能向坏块写入,这就意味着在NAND器件上自始至终都必须进行虚拟映射。
软件支持
当讨论软件支持的时候,应该区别基本的读/写/擦操作和高一级的用于磁盘仿真和闪存管理算法的软件,包括性能优化。 在NOR器件上运行代码不需要任何的软件支持,在NAND器件上进行同样操作时,通常需要驱动程序,也就是内存技术驱动程序(MTD),NAND和NOR器件在进行写入和擦除操作时都需要MTD。 使用NOR器件时所需要的MTD要相对少一些,许多厂商都提供用于NOR器件的更高级软件,这其中包括M-System的TrueFFS驱动,该驱动被Wind River System、Microsoft、QNX Software System、Symbian和Intel等厂商所采用。驱动还用于对DiskOnChip产品进行仿真和NAND闪存的管理,包括纠错、坏块处理和损耗平衡。
SSD,eMMC,UFS的区别
三者都是基于Nand的块设备。
SSD 主要作用是取代 PC/服务器 上的 HDD 硬盘,它需要:
- 超大容量(百GB~TB级别)
- 极高的并行性以提高性能
- 对功耗,体积等要求并不敏感
- 兼容已有接口技术 (SATA,PCI等)
而 eMMC 和 UFS主要都是针对移动设备发明的,它们需要:
- 适当的容量
- 适当的性能
- 对功耗 ,体积的要求极其敏感
- 仅需遵循一定的接口标准
一个SSD,为了达到高并行高性能的要求,有多个Flash 芯片,这样就可以在每个芯片上进行相互独立的读写操作,以并行性来提高硬盘吞吐量,还可以增加冗余备份。而手机中为了节省空间和功耗,通常只有一片密度较高的 Flash 芯片。
管理一个 Flash 芯片,和管理多个 Flash 芯片,策略肯定是不一样的,因此它们的控制器 (controller)就完全不同了。而且 PC 上需要兼容 SATA 或 PCIe 或 m2 接口,这样你电脑硬盘坏了的时候,可以拔下来换上另一块同样接口的硬盘能照样用。而手机上的 Flash 芯片大多是直接焊在主板上的,基本上不需要考虑更换的问题,所以只要遵从一个特定标准,能和CPU正常通讯就好了。因此接口的不同也是 SSD 和 eMMC,UFS 的重要区别之一。
eMMC 和 UFS 都是面向移动端 Flash 的标准,区别在于,二者的接口技术大相径庭。eMMC 和 MMC一样,沿用了 8 bit 的并行接口。在传输速率不高的时代,这个接口够用了。但随着设备对接口的带宽要求越来越高,想把并行接口速率提高也越来越难。eMMC 的最新 5.1标准理论最高值最高可以达到400 MB/s,再往上提高频率也不是不行,但就未必划算了。
好在这几年接口串行化大潮轰轰烈烈。所谓接口串行化,简单来说就是工程师们发现:与其用一个比较宽的并行接口以较低的速率传输,用一个串行接口用非常高的速率传输似乎更划算一些(带宽,功率,成本各方面综合考虑)。所以这个时候 UFS 应运而生,用高速串行接口取代了并行接口,而且还是全双工的,也就是可以读写同时进行。所以相比 eMMC, UFS的理论性能提高不少,甚至可以达到一些SSD的水准。
FTL
本职工作:地址映射。原因是闪存只能异地更新,为了对上支持数据块原地更新则需要通过地址转换实现。
由于闪存先擦后写、擦写有次数限制(寿命)、使用过程中会不断出现坏块(块寿命不同)等特性,FTL还需具备垃圾回收、磨损均衡、坏块管理等十八般武艺。
映射方式
闪存内部的基本存储单位是Page(4KB),N个Page组成一个Block。
块级映射
将块映射地址分为两部分:块地址和块内偏移。映射表只保存块的映射关系,块内偏移直接对应。
页级映射
映射表维护每个页的映射关系。
混合映射
主要思路是针对频繁更新的数据采用页级映射,很少更新的数据采用块级映射。其中采用Log Structed思想的混合映射将存储分为数据块(Data Block)和日志块(Log Block)。数据块用于存储数据,采用块级映射,日志块用于存储对于数据块更新后的数据,采用页级映射。混合映射是低端SSD、eMMC、UFS广泛采用的映射方式。根据日志块和数据块的对应关系又可以分为全相关映射(FAST)、块相关映射(BAST)、组相关映射(SAST)等等。下图是SAST映射的一个示例:2个日志块对应4个数据块,当日志块用完时需要通过搬移有效数据回收日志块。对于顺序写场景,最好情况下日志块对应位置记录了数据块的更新,则可以无需搬移数据,直接将日志块作为新的数据块(?),数据块进行擦除操作作为新的日志块。对于大量随机写场景,则需要将日志块和数据块中的有效数据搬移到空闲块的对应位置作为新的数据块,然后擦除原日志块和数据块。
XIP:eXecute In Place
XIP(Execute-In-Place)是一种存储器访问模式,允许 CPU 直接从存储器中执行代码,而无需将代码加载到 RAM 中。这种模式可以提高系统性能,减少 RAM 的使用,以及降低系统成本。
.png)
XIP 适用于需要快速执行代码的应用,例如嵌入式系统、网络设备、汽车电子等。在这些应用中,启动时间和响应速度非常重要,因此使用 XIP 可以显著提高系统性能和响应速度。
需要注意的是,XIP 模式并不适用于所有类型的存储器。只有一些特殊的存储器类型,如 NOR Flash,才支持 XIP。这是因为这些存储器类型具有快速的访问速度和随机读取功能,可以满足 XIP 模式的要求。
那么,NandFlash 是否支持 XIP 呢?当前实际有一些相关研究,不过大部分的结论都是「可以,但是没必要」。
痞子衡嵌入式:串行NAND Flash的两大特性导致其在i.MXRT FlexSPI下无法XiP - 痞子衡 - 博客园
主要阻碍 NandFlash 的 XIP 的有几点:
- 坏块导致的非线性存储:对于屏蔽坏块造成的非线性地址,程序无法正确处理,即无法自动跳过这些地址。
- NandFlash 上自带的 ECC 校验很大延迟:主机只能主动询问 Nand 是否校验完成
- NandFlash 本身延迟大,一般存储逻辑是按块、页读取而不是串行读取
Flash 嵌入式文件系统
嵌入式系统中 Flash 和文件系统的应用
{% embed url="https://elinux.org/images/4/44/Squashfs_eng.pdf" %}
.png)
.png)
.png)
多数嵌入式解决方案都是把压缩后的固件存储到 Flash 中,启动时解压到 RAM 中再在 RAM 上启动
可以改进的点:
- 压缩状态下的文件系统无法直接 XIP,需要在内存中先解压。如果可以联系 DDR 的特性,能不能做到直接解压执行,或者边解压边执行?
- Cramfs/Squashfs 都是只读文件系统,不能进行在线修改,在嵌入式场景下只能对整个文件系统做在线升级,不能做部分升级。
- 能不能改成可读写的文件系统?
- 能不能做部分 OTA?能不能做分区?
wear leveling:磨损均衡
Linux MTD 设备专门用于 Flash 这种存储介质,提供读、写、擦除方法。
在 Linux MTD 设备中,没有算法专门做磨损均衡,但是 UBI 有这个算法。.png)
.png)
UBIFS 运行在 UBI 之上,所以这个文件系统本身并不需要考虑磨损均衡,这是下一层的 UBI 逻辑。
yaffs2 等就没有磨损均衡了。
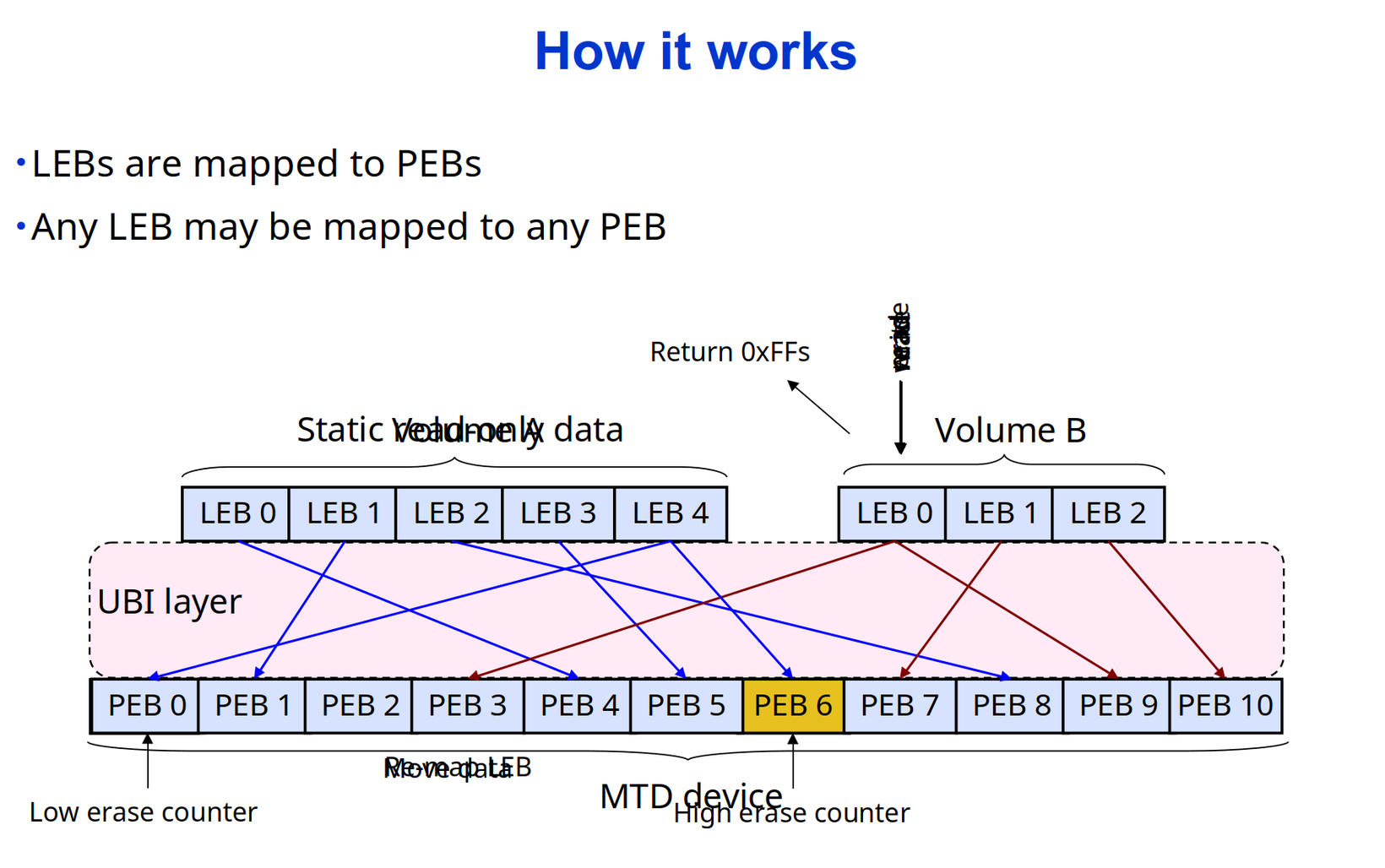
UBI:Unsorted Block Images
{% embed url="http://www.linux-mtd.infradead.org/doc/ubi.ppt" %}
.png)
Memory Technology Device (MTD) Subsystem for Linux.
- UBI 不是闪存转换层 (FTL),与 FTL 没有任何关系;
- UBI 与裸 Flash 一起工作,不适用于消费级闪存,例如 MMC、RS-MMC、eMMC、SD、mini-SD、micro-SD、CF、MemoryStick、USB 闪存驱动器等;相反,UBI 适用于原始闪存设备,这些设备主要用于嵌入式设备中,如手机等。
请不要混淆。请参阅此处了解有关原始闪存设备与 FTL 设备的更多信息。
UBI (Latin: "where?") 代表着 "Unsorted Block Images"。它是一个为裸 Flash 设备管理多个逻辑卷的卷管理系统,并将 I/O 负载(如均衡)分布在整个闪存芯片上。
在某种程度上,UBI 可以与逻辑卷管理器(LVM)进行比较。虽然 LVM 将逻辑扇区映射到物理扇区,但 UBI 则将逻辑擦除块映射到物理擦除块。但除了映射之外,UBI 还实现了全局均衡和透明的错误处理。
UBI 卷是一组连续的逻辑擦除块(LEB)。每个逻辑擦除块都会动态地映射到物理擦除块(PEB)。这个映射由 UBI 管理,并且对用户和高级软件来说是隐藏的。UBI 是提供全局均衡、每个物理擦除块擦除计数器以及透明地将数据从更磨损的物理擦除块移动到更不磨损的擦除块的基础机制。
当创建卷时,指定 UBI 卷大小,但可以稍后更改(可以动态调整卷大小)。有一些用户空间工具可用于操作 UBI 卷。
有两种类型的 UBI 卷:动态卷和静态卷。静态卷是只读的,并且其内容受到 CRC-32 校验和的保护,而动态卷是可读可写的,上层(例如,文件系统)负责确保数据完整性。
静态卷通常用于内核、initramfs 和 dtb。打开较大的静态卷可能会产生显著的惩罚,因为此时需要计算 CRC-32。如果您想将静态卷用于内核、initramfs 或 dtb 以外的任何内容,则可能会出现问题,最好改用动态卷。
UBI 知道坏的擦除块(即随着时间的推移而磨损的闪存部分)并使上层软件无需处理坏的擦除块。UBI 有一组保留的物理擦除块,在物理擦除块变坏时,它会透明地用好的物理擦除块替换它。 UBI 将新发现的坏物理擦除块中的数据移动到好的擦除块中。其结果是,UBI 卷的用户不会注意到 I/O 错误,因为 UBI 会透明地处理它们。
NAND 闪存也容易出现读写操作上的位翻转错误。通过 ECC 校验和可以纠正位翻转,但它们可能随着时间的推移而累积并导致数据丢失。UBI 通过将具有位翻转的物理擦除块中的数据移动到其他物理擦除块中来解决此问题。此过程称为scrubbing。Scrubbing 在后台透明地完成,上层软件不会注意到。
以下是 UBI 的主要特点:
- UBI 提供可以动态创建、删除或调整大小的卷;➡️类似 LVM 功能
- UBI 在整个闪存设备上实现磨损平衡(即,您可能认为您正在连续写入/擦除 UBI 卷的同一逻辑擦除块,但 UBI 将将其扩展到闪存芯片的所有物理擦除块);➡️类似 FTL 的软件磨损均衡实现
- UBI 透明地处理坏的物理擦除块;➡️NandFlash 坏块处理
- UBI 通过刷卡来最小化数据丢失的可能性。➡️针对性预防 NandFlash 数据错误
有一个名为 gluebi 的附加驱动程序,它在 UBI 卷的顶部模拟 MTD 设备。这看起来有点奇怪,因为 UBI 在 MTD 设备的顶部工作,然后 gluebi 在其上模拟其他 MTD 设备,但这实际上是可行的,并使得现有软件(例如 JFFS2)能够在 UBI 卷上运行。但是,新软件可能会从UBI的高级功能中受益,并让UBI解决许多闪存技术带来的问题。➡️可以通过兼容层将上述功能添加到其他 MTD 文件系统而无需修改代码。
UBI 与 MTD 的比较:https://www.cnblogs.com/gmpy/p/10874475.html
- Flash驱动直接操作设备,而MTD在Flash驱动之上,向上呈现统一的操作接口。所以MTD的"使命"是 屏蔽不同 Flash 的操作差异,向上提供统一的操作接口 。
- UBI基于MTD,那么UBI的目的是什么呢? 在MTD上实现 Nand 特性的管理逻辑,向上屏蔽 Nand 的特性 。
OverlayFS
OverlayFS 是一种联合文件系统,可以将多个文件系统层叠在一起,形成一个虚拟文件系统。OverlayFS 的特点包括:
- 可写层和只读层:OverlayFS 将多个文件系统层叠在一起,其中一个文件系统为可写层,其他文件系统为只读层。可写层可以包含新文件和修改文件,只读层包含原始文件和只读文件。
- 高效存储:OverlayFS 可以将多个文件系统的内容合并到一个虚拟文件系统中,避免重复存储和占用过多的存储空间。此外,OverlayFS 还支持 Copy-on-Write(写时复制)技术,可以减少文件系统的复制和移动操作,提高存储效率。
- 高性能:OverlayFS 可以在运行时将多个文件系统层叠在一起,形成一个虚拟文件系统。这可以减少文件系统的访问时间和提高系统性能。此外,OverlayFS 还支持内核级别的缓存和预读技术,可以提高文件系统的访问速度和性能。
- 支持多种文件系统格式:OverlayFS 支持多种文件系统格式,包括 ext4、XFS、Btrfs 等。这使得 OverlayFS 可以与不同的文件系统互操作,并提供更多的灵活性和可扩展性。
总的来说,OverlayFS 是一种高效存储和高性能的联合文件系统,可以将多个文件系统层叠在一起,形成一个虚拟文件系统。它适用于需要处理多个文件系统和提高系统性能的应用,例如容器、虚拟机、分布式存储等。
OpenWRT 中使用到了 OverlayFS 这一技术:https://openwrt.org/zh/docs/techref/filesystems
.png)
OverlayFS基本结构:多个文件系统的堆叠和合并
将 FUSE 和 OverlayFS 结合:https://github.com/containers/fuse-overlayfs
利用 OverlayFS 完成文件系统热迁移:https://github.com/stanford-rc/fuse-migratefs
F2FS
LFS
日志中包含索引信息,文件可以被高效的读出。为了快速的写入需要保留大块的空闲区域,可以将日志分成多个固定大小的连续空间——段(segment),在空闲区域不足时通过在碎片化的段中搬移有效数据回收新的连续空间。
日志结构文件系统如此优秀的写入性能不是没有代价的,如何高效的进行垃圾回收同时保持较高的写入性能,特别是剩余空间较少、碎片化严重后的性能一直是众多日志结构文件系统致力于解决的问题。
Checkpoint
文件系统某一时刻的快照。指文件系统某一时点所有文件系统有效数据、索引结构一致完整的记录。
创建检查点通常分两步:
- 落盘所有文件数据、索引、inode表、段使用情况表
- 在固定的检查点区记录所有有效的inode表和段使用情况表地址以及时间戳等。为了应对检查点过程中的系统崩溃,实际有两个检查点区交替更新(?)。由于时间戳是检查点最后更新的内容,每次重启后只需选择最新的检查点区即可保证有效性。在恢复到检查点后,还可根据日志记录继续前向恢复(roll-forward)数据。F2FS就针对单个文件的fsync实现了前向恢复能力,fsync时只需落盘文件数据和其直接索引。
除了超级块和检查点是保存在固定位置的,其他元数据和数据都是异地更新的日志。
F2FS
NAT
直接指向数据块的索引节点存的是虚拟地址,实际地址要到NAT表里查找,在更新数据时只需要更新NAT表,不需要递归地更新各级索引节点。(!)
inline data
支持数据直接存储在inode中。
冷热数据分离
将数据区划分为多个不同冷热程度的Zone。如:目录文件的inode和直接索引更新频繁计入热节点区,多媒体文件数据和回收中被搬移的数据计入冷数据区。冷热分离的目的是使得各个区域数据更新的频率接近。冷数据大多数保持有效因而无需搬移,热数据大多数更新后处于无效状态只需少量搬移。目前F2FS的冷热分离还较为简单,结合应用场景有很大的优化空间。(!)
垃圾回收
F2FS的垃圾回收Garbage Collection(GC)分为前台GC和后台GC。当没有足够空闲Section时会触发前台GC,内核线程也会定期执行后台GC尝试清理。另外F2FS也会预留少量空间,保证GC在任何情况下都有足够空间存放搬移数据。GC过程分三步:
1)搬移目标选择,两个著名的选择算法分别是贪心和成本最优(cost-benefit)。 贪心算法挑选有效块最少的Section,一般用于前台GC以减少对IO的阻塞时间。 Cost-benefit算法主要用于后台GC,综合了有效块数和Section中段的年龄(由SIT中Segment的更新时间计算)。该算法的主要思想是识别出冷数据进行搬移,热数据可能再接下来一段时间被更新无需搬移,这也是进行动态冷热分离的又一次机会。
2)识别有效块并搬移,从SIT中可以获取所有有效块,然后在SSA中可以检索其父亲节点块信息。对于后台GC,F2FS并不会立即产生迁移块的I/O,而只是将相关数据块读入页缓存并标记为脏页交由后台回写进程处理。这个方式既能减少对其他I/O的影响,也有聚合、消除小的分散写的作用。
3) 后续处理,迁移后的Section被标记为“预释放”状态,当下一个检查点完成中Section才真正变为空闲可被使用。因为检查点完成之前掉电后会恢复到前一个检查点,在前一个检查点中该Section还包含有效数据。
当空闲空间不足时,F2FS也不是“一根筋”的继续保持日志写的方式(Normal Logging)。直接向碎片化的Segment中的无效块写入数据是日志结构文件系统的另一个日志策略(Threaded Logging),又被称为SSR(Slack Space Recycling)。SSR虽然变成了随机写,但避免了被前台GC阻塞。同时通过以贪心方式选择做SSR的Section,写入位置仍然有一定的连续性。
********F2FS性能对比**********
F2FS vs. EXT4 File-System Performance With Intel's Clear Linux
-
SQLite 非常快

-
随机读写比 Ext4 稍微弱
-
文件系统同步(sync)性能比 Ext4 好很多
-
PostgreSQL 测试 F2FS 比 Ext4 性能差了一大截
-
Systemd 启动,F2FS 比 Ext4 慢
已知的问题
https://wiki.archlinux.org/title/F2FS
-
版本稳定性问题:
如果在运行机器上的内核版本旧于用于创建分区的内核版本,则F2FS分区中包含的数据可能无法使用。例如,如果F2FS分区是在由linux提供的主线内核上创建的,但系统需要降级到由linux-lts提供的较旧的内核系列,则可能会出现此限制。请参见FS#69363。
-
磁盘修复问题 fsck failures
-
GRUB 启动问题
尽管 GRUB 自 2.0.4 版本支持 F2FS,但它无法从启用了
extra_attr标志的 F2FS 分区正确读取其引导文件(有关更多详细信息,请参见 GRUB#不支持的文件系统)。 -
写入放大问题,造成 SSD 寿命缩短
-
Nand 过度配置问题
-
段清理开销
-
元数据更新开销
-
文件碎片
-
冷热数据识别不够智能
F2FS 优化分析
F2FS 的缺点和可优化点包括:段清理开销、元数据更新开销、文件碎片、顺序读取性能差等。这些优化点与以下论文相关联:
- When F2FS Meets Address Remapping:利用地址重映射技术来弥补 F2FS 中的缺陷,达到原地更新的效果,避免段清理、元数据更新和文件碎片的问题。
- M2H: Optimizing F2FS via Multi-log Delayed Writing and Modified Segment Cleaning based on Dynamically Identified Hotness:基于动态识别热点,利用多日志延迟写入和修改段清理来优化 F2FS 的性能。
- Mitigating Synchronous I/O Overhead in File Systems on Open-Channel SSDs:通过引入内置的持久暂存层来提供对闪存友好的数据布局,以提供平衡的读取、写入和垃圾收集性能。
- Optimizing Fragmentation and Segment Cleaning for CPS based Storage Devices:提出了多级阈值同步写入方案和高检测频率背景段清理方案来减少段清理的开销。
ZNS
block based flash的问题
Flash必须先擦除再写,擦除的最小粒度大于写入的最小粒度 =>异地更新 =>使用FTL负责地址映射,垃圾回收、磨损均衡、坏块管理等 =>不同文件的数据杂糅在一起 =>先移动有效数据到OP,才能擦除数据(垃圾回收)=>OP浪费空间,移动有效数据浪费时间=>换一种思路
ZNS的效果
ZNS-SSD的吞吐和延时不受GC影响,且不需要额外的OP空间。 zenfs是端到端的数据访问,不会再走内核庞大的I/O调度逻辑。
ZNS的细节
将整个SSD内部的存储区域分为多个zone 空间。不同的zone 空间之间的数据可以是独立的。最主要的是,每一个zone 内部的写入 只允许顺序写,可以随机读。为了保证zone 内部的顺序写,在ZNS内部想要覆盖写一段LBA地址的话需要先reset(清理当前地址的数据),才能重新顺序写这一段逻辑地址空间。
不需要垃圾回收,需要上层软件配合,保证一个zone在全部数据失效的时候擦除。
ZNS 的结构:Zone
摘自 /usr/include/linux/blkzoned.h:
/**
* enum blk_zone_type - Types of zones allowed in a zoned device.
*
* @BLK_ZONE_TYPE_CONVENTIONAL: The zone has no write pointer and can be writen
* randomly. Zone reset has no effect on the zone.
* @BLK_ZONE_TYPE_SEQWRITE_REQ: The zone must be written sequentially
* @BLK_ZONE_TYPE_SEQWRITE_PREF: The zone can be written non-sequentially
*
* Any other value not defined is reserved and must be considered as invalid.
*/
enum blk_zone_type {
BLK_ZONE_TYPE_CONVENTIONAL = 0x1,
BLK_ZONE_TYPE_SEQWRITE_REQ = 0x2,
BLK_ZONE_TYPE_SEQWRITE_PREF = 0x3,
};
摘自 libzbd/zdb.h:
/**
* @brief Zone types
*
* @ZBD_ZONE_TYPE_CNV: The zone has no write pointer and can be writen
* randomly. Zone reset has no effect on the zone.
* @ZBD_ZONE_TYPE_SWR: The zone must be written sequentially
* @ZBD_ZONE_TYPE_SWP: The zone can be written randomly
*/
enum zbd_zone_type {
ZBD_ZONE_TYPE_CNV = BLK_ZONE_TYPE_CONVENTIONAL,
ZBD_ZONE_TYPE_SWR = BLK_ZONE_TYPE_SEQWRITE_REQ,
ZBD_ZONE_TYPE_SWP = BLK_ZONE_TYPE_SEQWRITE_PREF,
};
Zone 的分类:
- Conventional Zone
- 块内地址能够随机写
- 没有写指针机制(与普通 SSD 一致)
- Reset 对这种 Zone 无效
- Sequentially Write Required Zone
- 不能随机写,必须从当前 Zone 的写指针开始顺序写
- 可以 Reset 来清除指针值
Zenfs
Linux内核对ZNS的支持
ZNS的特性 需要内核支持,所以开发了ZBD(zoned block device) 内核子系统 来提供通用的块层访问接口。除了支持内核通过ZBD 访问ZNS之外,还提供了用户API ioctl进行一些基础数据的访问,包括:当前环境 zone 设备的枚举,展示已有的zone的信息 ,管理某一个具体的zone(比如reset)。
在近期,为了更友好得评估ZNS-ssd的性能,在ZBD 上支持了暴露 per zone capacity 和 active zones limit。
Zenfs代码分析
TODO
LIZA:通过LSM的层级结构预测每个SSTable的生命周期,把具有相似生命周期的数据放到同一个zone中,以减小GC过程中迁移有效数据的开销。这种预测方式显然不够准确,举个例子,参与compact并合并成一个SSTable的多个SSTable是同时失效的,但是这多个SSTable不一定在同一个level,如果使用LIZA算法,也就不一定在同一个zone。
CAZA:SSTable的删除时间仅仅由compact过程决定。compact过程把相邻层级的具有重叠key范围的SSTable合并,因此CAZA把新创建的SSTable放在拥有最多和这个SSTable重叠key范围的zone中,在compact触发时,这些SSTable被同时compact,同时失效。
题目描述与分析
项目描述
Flash介质因本身的擦除特性,给上层文件系统带来与普通磁盘、内存文件系统不同的数据管理模式。同时,Flash的写入放大、寿命以及后期稳定性下降等问题也给文件系统的设计带来的一定的挑战。传统的Flash文件系统并没有很好地解决这些稳定性相关问题。这里希望寻找一种更智能、更合适的Flash文件系统设计,来更好地平衡Flash的性能与稳定性。可以思考的方向包括但不限于:数据压缩算法(可以是自适应的压缩算法),检错、纠错、纠删码(可以是联合信源信道编码),数据块选择、擦除策略,Cache机制。
项目导师
- 郑立铭
- email: zhengliming3@huawei.com
难度
中等
特征
- 完成基本的文件系统的功能。
- 合理地使用数据压缩方案,平衡计算性能与Flash写入性能。
- 设计擦除块选择算法、数据块迁移算法,平衡各擦除块寿命、减少写入放大。
进阶特性
- 设计写入Cache,提升写入速率,同时需要考虑数据的一致性与可持久化(可以说是掉电)问题,可以结合类似Trim的机制。
- 设计一个自适应的Flash纠错编码。识别Flash的生命周期,在Flash的生命周期前期倾向性能,后期倾向稳定性。
**概括:**要求设计一个更智能的 Flash 文件系统,包括以下特性:
- 完成基本的文件系统的功能。
- 合理地使用数据压缩方案,平衡计算性能与 Flash 写入性能。
- 设计擦除块选择算法、数据块迁移算法,平衡各擦除块寿命、减少写入放大。
- 设计写入 Cache,提升写入速率,同时需要考虑数据的一致性与可持久化问题,可以结合类似 Trim 的机制。
- 设计一个自适应的 Flash 纠错编码。识别 Flash 的生命周期,在 Flash 的生命周期前期倾向性能,后期倾向稳定性。
题目分析
题目分析
题目中指定的技术点
- 数据压缩算法(可以是自适应的压缩算法)
- 检错、纠错、纠删码**(可以是联合信源信道编码)**
- 数据块选择、擦除策略(仅裸 Flash)
- Cache 机制
- 『智能』如果可以是机器学习,要如何结合
以上加粗的是上一届项目中没有涉及或者说注重的点。
⚠️特别注意
- 在往届队伍实现中的『Flash』指的是『裸Flash』,即嵌入式设备中常用的可以指定绝对写入地址的 Flash 环境。如果理解为用于 SSD 等『基于 Flash 的存储设备』,则实现逻辑和题目要求可能南辕北辙。其 UBIFS 和改进是针对裸 Flash 设计的。
往年实现分析
往年实现分析
编译通过求求了 / proj117-基于UBIFS的更智能的文件系统
注重的地方
-
文档数量庞大。
文档中需要包含整个开发流程,需要列举并详细说明涉及到的技术要点和原理,以及配有丰富的示意图和代码段。
在这个队伍的文档实现中,很大部分是分析原版 UBIFS 的实现逻辑和代码理解,另外一部分有基于这些理解对技术进行的调研以及自己的实现逻辑。
-
总代码大。
去除重复文件后统计文件行数如下:
------------------------------------------------------------------------------- Language files blank comment code ------------------------------------------------------------------------------- C 48 6044 12432 30124 C/C++ Header 13 713 4033 4173 ------------------------------------------------------------------------------- SUM: 61 6757 16465 34297 -------------------------------------------------------------------------------看起来原版 UBIFS 的代码量就是很大,总大小有 1.5MiB,队伍自己的实现暂未统计。
-
从「智能」这一点出发。
PPT:
- 『智能:针对不同的情况能够进行不同的处理,从而提升整体性能』
- 『相较于ai,其只是低级层面的智能』
项目中「智能」的实现:
- 通过判断文件名的方式来判断使用的压缩算法和参数,即压缩算法和等级的自适应
- 通过检查压缩效果是否合适来判断是否继续压缩,压缩效果不好可能其数据本身就是压缩文件,则再次不压缩
- 利用文件系统中的局部性
- 在 Flash 后期容易产生错误的时候转用纠错能力更强的算法
- 冷热数据判别
-
UBIFS 部分使用到了 Log-Structured 文件系统,即划分了一部分空间来给 Journal 做直接写入
可以改进的地方
-
联系题目,有没有没有做的点?
- 纠删码(可以是联合信源信道编码)
- 数据块选择、擦除策略
- Cache 机制
-
测试、展示不够规范。
-
演示视频中,不断切换测试脚本和开发环境,并通过切换分支的方式切换功能和版本。
这样看视频的人很难看懂在做什么,看懂了也很难说明当前的设计有哪些提升。如果演示的时候就能直观地用自动化脚本生成测试报告,如表格、统计图等,会更加有表现力,更能说服评委。
-
没有使用通用的测试脚本或者软件,而是选择自己写脚本测试,难以说明提升。
测试中大部分测试使用 3~11MiB 大小的连续读写,或者直接使用上百 MiB 的大文件连续读写,这不仅不能说明问题,而且也没有解决实际问题。在复杂的文件读写环境中,大部分读写应该是 4KiB 随机读写,这在其他的文件系统论文中是最重要的指标之一,视频中没有体现。
-
-
测试环境不对。
既然是适用于 Flash 的文件系统,就应该统计和 Flash 相关的数据,从而衡量这个文件系统对 Flash 的稳定性、寿命、速度的综合影响,但是测试中只是在本机上进行了速度的测试,这难以说明问题。
我的提议是建立一个 Flash 仿真程序,真正计算在 Flash 中的读写频率、位置等信息,并模拟 Flash 芯片的具体延迟给出具体读写速度。
其次,对 Flash 芯片的检错、纠错测试也应该基于 Flash 仿真,而不是在内存中写入值。
⚠️可能能够仿真的只有裸 Flash 环境。
-
性能并不算非常优秀。
有些展示出来的功能点,还不如原版 UBIFS,不过优化的点看起来数据都不错。
-
纠错算法和 UBIFS 本身不太兼容。
-
如果实现机器学习层面的『智能』?
-
UBIFS 本身是 2009 年的论文,应该在此基础上也有更多的优化实现。
-
功能拓展
-
与嵌入式功能结合:如果将内存的一部分放到 Flash 上做 Swap,能不能在文件系统层面做优化
-
与 SSD 主控的功能结合:项目中没有实现 Trim 方案,即自动数据整理,我们可以针对这个功能点做实现。(如果是基于有 FTL 的 Flash,这个可能就做不到)
-
与 SSD 算法结合:Flash 做块擦除更方便,能不能结合硬件信息做块擦除(仅 裸 Flash?)
-
更新的技术:
- 有没有更好的纠错码?SSD 内部一般用什么算法?适合软件模拟吗?
- 有没有能结合 CPU Cache 和 Flash Cache 的算法?怎么实现?
-
AI 怎么说:结合 SSD 主控原理分析本题的更多突破口
- 更好的垃圾回收算法:在 SSD 中,垃圾回收算法是一个非常重要的算法,可以考虑将 SSD 中的垃圾回收算法与 Flash 文件系统中的垃圾回收算法相结合,从而提高 Flash 文件系统的性能和稳定性。
- 更好的预测算法:在 SSD 中,预测算法可以帮助提高读取性能和减少读取延迟,可以考虑将预测算法与 Flash 文件系统中的读取算法相结合,从而提高 Flash 文件系统的读取性能和稳定性。
- 更好的写入算法:在 SSD 中,写入算法可以帮助提高写入性能和减少写入延迟,可以考虑将写入算法与 Flash 文件系统中的写入算法相结合,从而提高 Flash 文件系统的写入性能和稳定性。
- 更好的数据压缩算法:在 SSD 中,数据压缩算法可以帮助提高存储密度和减少读取和写入延迟,可以考虑将数据压缩算法与 Flash 文件系统中的数据压缩算法相结合,从而提高 Flash 文件系统的存储密度和稳定性。
- 更好的数据分配算法:在 SSD 中,数据分配算法可以帮助提高存储效率和减少写入延迟,可以考虑将数据分配算法与 Flash 文件系统中的数据分配算法相结合,从而提高 Flash 文件系统的存储效率和稳定性。
- 更好的**数据保护(安全性)**算法:在 SSD 中,数据保护算法可以帮助提高数据的安全性和可靠性,可以考虑将数据保护算法与 Flash 文件系统中的数据保护算法相结合,从而提高 Flash 文件系统的安全性和可靠性。
- 更好的**块管理(与实际硬件数据结合)**算法:在 SSD 中,块管理算法可以帮助提高存储效率和减少写入延迟,可以考虑将块管理算法与 Flash 文件系统中的块管理算法相结合,从而提高 Flash 文件系统的存储效率和稳定性。
- 更好的缓存算法:在 SSD 中,缓存算法可以帮助提高读取性能和减少读取延迟,可以考虑将缓存算法与 Flash 文件系统中的缓存算法相结合,从而提高 Flash 文件系统的读取性能和稳定性。
- 更好的并发算法:在 SSD 中,并发算法可以帮助提高存储效率和减少写入延迟,可以考虑将并发算法与 Flash 文件系统中的并发算法相结合,从而提高 Flash 文件系统的存储效率和稳定性。
- 更好的数据清理算法:在 SSD 中,数据清理算法可以帮助提高存储效率和减少写入延迟,可以考虑将数据清理算法与 Flash 文件系统中的数据清理算法相结合,从而提高 Flash 文件系统的存储效率和稳定性。
嗯……比我想的周全。
-
问题列表
RAID 相关
-
SSD 的磨损 / 损坏情况是怎样的
Chiro:如果一次就会使得一整个盘坏掉,那 Zones 级别的 RAID 意义可能不大。
老师:其实商用 SSD 的损坏情况和消费级的是不一样的,消费级的一般一次坏掉一整个盘,但是商用的话需要尽可能完全使用 SSD 的每个颗粒,如果颗粒寿命耗尽会屏蔽掉这个颗粒然后继续使用。我可以给你们一篇谷歌在这方面数据的论文。(Flash Reliability in Production: The Expected and the Unexpected)
-
基于 Zones 的 RAID 和普通的 RAID,区别和改进是什么?
-
提高区域利用性:当一个商用 ZNS 只坏掉了一个区域,可以用 RAID 的冗余特性将数据恢复并屏蔽相关区域,就可以继续运行,完全压榨所有颗粒的寿命。
-
提高读写带宽:
当使用多个设备的时候,均衡分配块的读写。
- 如何分配不同的
devices的 Open Zones? - 如何使 Read / Write 尽量应用不同设备的更多的 Open Zones 来提高整体带宽?
- 如何分配不同的
-
-
RAID5 为什么要错开校验存储?
调参相关
-
ZenFS 相关的参数可能比较少,如果进行调参工作的话工作空间有限
老师:其实不需要将视野局限于 ZenFS 这一个文件系统,如果能够在 ZNS 上做多种文件系统的调参,工作层次就能打开了。例如,做在 ZNS 上实现的 F2FS、btrfs 的调参等。
-
对训练数据还没收集积累,收集数据时间可能不够
-
数据调参的逻辑解释
-
扩充参数
-
动态调参的详细过程
在系统运行当中,调参模块只能获取到系统在一段时间上的数据,没法启动更多测试进程来收集新数据,如何做动态调参?
-
调参的视频展示
应用相关
-
当前 ZenFS 的应用场景局限于 RocksDB 这一个单一的场景,但是能扩展的引用场景同样有限
Chiro:ZenFS 针对 RocksDB 到 ZNS 的读写而开发,中间的原理和逻辑并不复杂,但是正是因为其原理和逻辑很简单,没有做 POSIX 的访问接口;如果我们基于 ZenFS 去实现这一中接口,虽然可能是扩展了 ZenFS 以及相关 ZNS 的应用场景,但是性能和效果未必比西数官方在 ZNS 上的 F2FS、btrfs 的实现要好。
老师:基于 ZenFS 去专门实现一个 POSIX 的接口是可以的,因为 ZenFS 的架构和刚才你举例的那些文件系统都不一样,而且其原来的文件系统的简单正说明有很多创新的工作可以做。其次,可以进一步利用其顺序写的特性,扩展更多 RocksDB 外的存储专用的场景,例如其他的数据库到 LSM-Tree 的兼容。
几个相关研究方向的研究过程记录。
- RAID on ZNS
- 提升 ZNS 的扩展性,用于更多应用场景,并保持性能较高
-
使用 ML 技术等进行调参
- ML 训练数据
- 系统负载调参
- 健康度调参
-
TODO
- 多个文件系统的融合
- 基于 ZenFS 内的 Extent 或者 Record 的压缩
- io_uring 支持
- SPDK/NVME 支持
- 整体架构
作为RocksDB的插件的ZenFs源码剖析
底层ZBD相关
代码位于zbd_zenfs.h和zbd_zenfs.cc中
Zone抽象
class Zone {
ZonedBlockDevice *zbd_;
ZonedBlockDeviceBackend *zbd_be_;
std::atomic_bool busy_;
uint64_t start_;//起始物理地址
uint64_t capacity_; /* remaining capacity */
uint64_t max_capacity_;
uint64_t wp_;
Env::WriteLifeTimeHint lifetime_;
std::atomic<uint64_t> used_capacity_;
}
一个Zone需要有所属块设备,起始地址和写指针,生命周期和空间相关的维护。
Zone中的方法有重置Zone,判断是否为空或者是否写满,往写指针后面添加数据等等。
ZoneList抽象
class ZoneList {
private:
void *data_;
unsigned int zone_count_;
}
ZoneList指的是Zone的list。
ZonedBlockDeviceBackend接口
ZonedBlockDeviceBackend是用来和底层设备交互需要经过的接口,这个接口将底层的ZoneList全部抽象成内存中连续的ZoneList并进行操作。
在zbdlib_zenfs.h以及zbdlib_zenfs.cc实现接口以方便上层对底层zbd的访问。
在zonefs_zenfs.h以及zonefs_zenfs.cc的实现是将上层对zbd的访问通过posix的读写文件方式给包装起来。
class ZonedBlockDeviceBackend {
public:
uint32_t block_sz_ = 0;
uint64_t zone_sz_ = 0;
uint32_t nr_zones_ = 0;
}
backend有两种类型分别是:
enum class ZbdBackendType {
kBlockDev,
kZoneFS,
};
ZonedBlockDevice抽象
class ZonedBlockDevice {
private:
std::unique_ptr<ZonedBlockDeviceBackend> zbd_be_;
std::vector<Zone *> io_zones;//用于io的zone
std::vector<Zone *> meta_zones;//用于保存元信息的zone
time_t start_time_;
std::shared_ptr<Logger> logger_;
uint32_t finish_threshold_ = 0;
std::atomic<uint64_t> bytes_written_{0};
std::atomic<uint64_t> gc_bytes_written_{0};// 垃圾回收转移的字节数目
std::atomic<long> active_io_zones_;//分配io_zone时需要用锁
std::atomic<long> open_io_zones_;
/* Protects zone_resuorces_ condition variable, used
for notifying changes in open_io_zones_ */
std::mutex zone_resources_mtx_;
std::condition_variable zone_resources_;
std::mutex zone_deferred_status_mutex_;
IOStatus zone_deferred_status_;
std::condition_variable migrate_resource_;
std::mutex migrate_zone_mtx_;
std::atomic<bool> migrating_{false};
unsigned int max_nr_active_io_zones_;
unsigned int max_nr_open_io_zones_;
std::shared_ptr<ZenFSMetrics> metrics_;//todo
}
Open函数
用来打开一个ZonedBlockDevice,流程如下:
- 首先获取最大活跃io_zones数目和最大可打开io_zones,这里保留了一个zone用于metadata存储(todo:为什么实际上分配了三个zone),一个用于extent migration(todo)。
- 从backend中获取已有zones分配3个meta_zones。将剩余的非离线状态的可获得的zone放入io_zones中。遍历的过程可统计当前活跃zone的数目
处于离线状态的块,也就是offline,指的是这个zone已经dead了,这里可以理解成已经坏掉了?todo
Get*Space函数
顾名思义,用来获取诸如已经使用空间,空闲空间以及可回收空间大小
Log*函数
用来输出日志,获取zone的整体使用情况,每个zone单个使用情况以及垃圾空间占比等。
分配zone区域方法
ZonedBlockDevice重要的功能应该是操作zone。
首先是分配释放相关操作:
-
ApplyFinishThreshold将剩余空间小于预设的块给finish掉,finish操作指的是把一个zone的写指针移动到zone末尾,剩余容量减为0。
-
FinishCheapestIOZone将一个最小剩余空间的zone给finish。
-
GetBestOpenZoneMatch将一个当前的文件生命周期和每一个io_zone进行生命周期对比,分配一个生命周期大于当前文件的生命周期且最接近的zone。
-
AllocateEmptyZone,顾名思义是分配一块空的zone。
-
ReleaseMigrateZone,顾名思义是释放migrate_zone (todo migrate zone是用来干嘛的)。
-
TakeMigrateZone,选择一块最优zone当作migrate_zone。
-
AllocateIOZone,在保持max_active_io_zones的数量的前提下分配一块zone。
-
Read,从偏移offset处读n个byte吧应该是,这里边用了ZonedDeviceBackend提供的Read接口。
此外还有一些有趣的方法比如说Read用ZonedBlockDeviceBackend实现的Read实现zone的读,以及一些设置zone的默认状态的方法。
实现ZonedBlockDeviceBackend接口
在前面已经提到过:
在zbdlib_zenfs.h以及zbdlib_zenfs.cc实现接口以方便上层对底层zbd的访问。
在zonefs_zenfs.h以及zonefs_zenfs.cc的实现是将上层对zbd的访问通过posix的读写文件方式给包装起来。
zbdlib_zenfs
zbdlib实现的接口更加接近于zbd的底层,它将zbd中的所有zone的元信息(struct zone)作为一个数组读到内存,通过元信息和zbd底层的接口进行交互。
zonefs_zenfs
zonefs中用操作系统的读写路径来操作zone,将每个zone抽象成一个文件进行读写。
这里采用LRU的策略维护内存中文件句柄的队列。
Snapshot
ZBD设备快照
class ZBDSnapshot {
public:
uint64_t free_space;//空闲空间
uint64_t used_space;//已使用空间
uint64_t reclaimable_space;//可回收空间
}
ZBD设备快照记录设备的空闲空间(free_space),已使用空间(used_space)和可回收空间(reclaimable_space)。
Zone快照
class ZoneSnapshot {
public:
uint64_t start;//Zone开始地址
uint64_t wp;//写指针
uint64_t capacity;//容量
uint64_t used_capacity;//已用容量
uint64_t max_capacity;//最大容量
}
Zone快照记录了Zone区域的开始地址(start),写指针(wp),以及容量相关信息。
ZoneExtent快照
class ZoneExtentSnapshot {
public:
uint64_t start;//todo
uint64_t length;//Extent长度
uint64_t zone_start;//todo
std::string filename;//Extent所属文件名
}
ZoneFile快照
class ZoneFileSnapshot {
public:
uint64_t file_id;//顾名思义 file的id
std::string filename;//文件名
std::vector<ZoneExtentSnapshot> extents;//文件的extents快照集合
}
论文中提到过一个文件拥有多个extent,extent不会跨Zone存储,在这些数据结构中可以看出端倪。
ZenFs快照
class ZenFSSnapshot {
public:
ZBDSnapshot zbd_;
std::vector<ZoneSnapshot> zones_;
std::vector<ZoneFileSnapshot> zone_files_;
std::vector<ZoneExtentSnapshot> extents_;
};
这里的快照便是之前所有快照的组合,所以ZenFs的内部结构也可以看的比较清楚。
io_zenfs
ZoneFs的文件内容是由多个extent组成的,每个extent都放在一个zone里面,extent不能跨zone存储。
在io_zenfs.h中定义了一些关键的数据结构,首先是extent:
class ZoneExtent {
public:
uint64_t start_;// 物理起始地址
uint64_t length_;// extent的长度
Zone* zone_;// 所属zone指针
explicit ZoneExtent(uint64_t start, uint64_t length, Zone* zone);
Status DecodeFrom(Slice* input);
void EncodeTo(std::string* output);
void EncodeJson(std::ostream& json_stream);
};
其次是zonefile:
class ZoneFile {
private:
const uint64_t NO_EXTENT = 0xffffffffffffffff;
ZonedBlockDevice* zbd_;
std::vector<ZoneExtent*> extents_;
std::vector<std::string> linkfiles_;
Zone* active_zone_;
uint64_t extent_start_ = NO_EXTENT;
uint64_t extent_filepos_ = 0;
Env::WriteLifeTimeHint lifetime_;
IOType io_type_; /* Only used when writing */
uint64_t file_size_;
uint64_t file_id_;
uint32_t nr_synced_extents_ = 0;
bool open_for_wr_ = false;
std::mutex open_for_wr_mtx_;
time_t m_time_;
bool is_sparse_ = false;
bool is_deleted_ = false;
MetadataWriter* metadata_writer_ = NULL;
std::mutex writer_mtx_;// zonefs的读写锁
std::atomic<int> readers_{0};
public:
static const int SPARSE_HEADER_SIZE = 8;
}
zonefile在操作时只会操作一个active_zone,同时文件记录了生命周期,读写锁等等。
其中实现的方法有稀疏文件append,所谓稀疏文件就是除了在zone中保存了有效数据信息之外还保存了有效数据的长度信息,如下图所示:
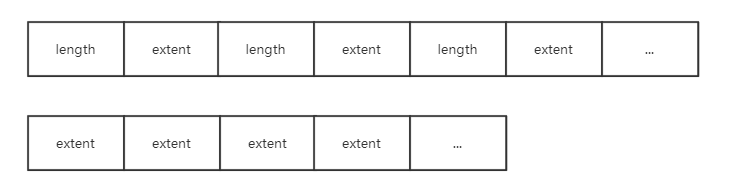
sparse方式的zone中会将长度记录计入,而普通的zone只会一直append文件中的extent。
除此之外,zonefs还有实现了RocksDB的FSWritableFile接口以支持顺序写的方法,实现了FSSequentialFile接口以实现顺序读,FSRandomAccessFile接口以实现随机读。
fs_zenfs
fs_zenfs.h和fs_zenfs.cc中记录的是最为核心的zenfs的文件逻辑。
首先是超级快superblock:
class Superblock {
uint32_t magic_ = 0;
char uuid_[37] = {0};
uint32_t sequence_ = 0;
uint32_t superblock_version_ = 0;
uint32_t flags_ = 0;
uint32_t block_size_ = 0; /* in bytes */
uint32_t zone_size_ = 0; /* in blocks */
uint32_t nr_zones_ = 0;
char aux_fs_path_[256] = {0};
uint32_t finish_treshold_ = 0;
char zenfs_version_[64]{0};
char reserved_[123] = {0};
}
然后是重要的zenmetalog,用于记录操作和恢复用:
class ZenMetaLog {
uint64_t read_pos_;
Zone* zone_;
ZonedBlockDevice* zbd_;
size_t bs_;
}
zenmetalog加入的record是如下形式,首先存储的是由长度和数据形成的冗余码,然后是数据长度,再是实际的数据。

每一次roll的操作都会重新开一个zone来记录metadata信息,时机是当这个zone写满了todo,而一个新的metazone的内容首先会加入下面内容,此时记录的是文件系统的瞬时状态也即snapshot,当然这些snapshot是用record的形式加入的:
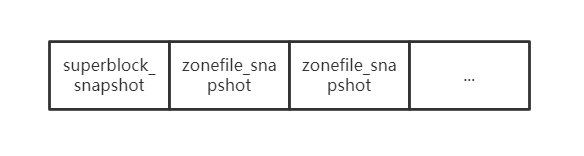
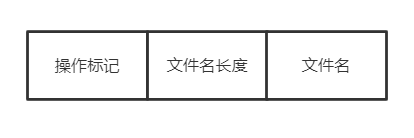
在update,replace或是delete文件时,都会按照如下格式包装成record加入metalog:
manipulate_form
ZenFs文件系统:
class ZenFS : public FileSystemWrapper {
ZonedBlockDevice* zbd_;
std::map<std::string, std::shared_ptr<ZoneFile>> files_;// ZoneFile
std::mutex files_mtx_;
std::shared_ptr<Logger> logger_;
std::atomic<uint64_t> next_file_id_;
Zone* cur_meta_zone_ = nullptr;
std::unique_ptr<ZenMetaLog> meta_log_;// 元信息
std::mutex metadata_sync_mtx_;
std::unique_ptr<Superblock> superblock_;// 超级块
std::shared_ptr<Logger> GetLogger() { return logger_; }
std::unique_ptr<std::thread> gc_worker_ = nullptr;// 垃圾回收
bool run_gc_worker_ = false;
}
GC_WORKER垃圾回收
当全局zone里边的free空间小于一定比例之后,gc_worker便开始了垃圾回收工作,核心思想便是:
收集需要垃圾回收的zone,即zone的剩余空间满足一定的条件就进行回收,之后将zone中对应的extent移动到与当前zonefile生命周期相匹配的zone,这个zone是顺序写的,这个移动extent的操作叫做migrate操作。
MOUNT逻辑
- 读入所有metazone并且读出superblock,选择seq序号最大的superblock的meta作为恢复zone。
- 若是readonly的,则从磁盘同步一次数据。
- 若是可写的,并且用一个新的metazone记录当前文件系统的瞬时状态(superblock以及各个zonefile的编码)。同时要将系统的未用zone重置一下。最后开启垃圾回收线程。
MKFS逻辑
- 选择一个metazone作为log记录的zone。
- 写入superblock和各个zonfile编码到metazone中。
ZenFs整体框架
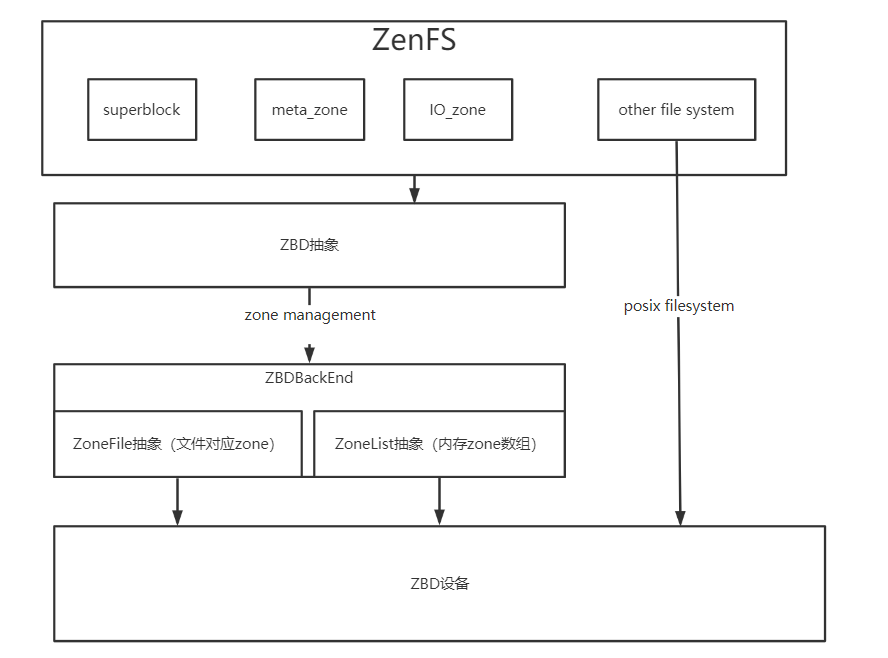
基于理解,绘制出ZenFs框架图如下:
RAID on ZNS
本方向将研究 RAID 技术在 ZNS 上的应用。
处于简化问题考虑,我们只研究相同型号 SSD 下的 RAID。
问题
-
RAID 种类和性能?ZFS在不同 RAID 策略下的性能评测
-
RAID 在 SSD 上如何实现比较好?
Parity-Stream Separation and SLC/MLC Convertible Programming for Lifespan and Performance Improvement of SSD RAIDs
-
ZNS 的 Zones 有两种:
seq/cnv。前者不能随机写入,只能顺序写入;后者可以随机写入,就像普通的硬盘一样。如何利用这两种 Zones 的特点在 ZNS 上运行 RAID 的算法?- 两种 Zone 的兼容问题
- Cnv Zones 兼容 Seq Zones,不过兼容会造成 FTL Map 空间的浪费
- SSD 块大小兼容问题
- 不同的 Seq 可以看作最小长度的多个 Seq Zones
- 不同的 Cnv Zones 可以划分为更小的小块来尽可能抹平
- Seq Zones 上如何实现各种 RAID 算法
- 两种 Zone 的兼容问题
-
RAID 的性能参数选择评估?如何设置 RAID 组的 Strip Size
RAID 是指独立冗余磁盘阵列(Redundant Array of Independent Disks),它是一种数据存储技术,通过将多个硬盘组合起来,实现数据的备份、容错和性能优化。
实现原理
经过一些讨论,我们认为基于 Zones 的混合 RAID 是可以实现的。
RAID0 逻辑
RAID0(磁盘条带化)是一种基本的RAID级别,它将两个或多个磁盘驱动器组合成一个逻辑卷。在RAID0中,数据被分割成固定大小的块,并沿着所有磁盘驱动器进行交错写入,从而提高了读写性能。
RAID0的工作原理如下:
- 数据被分割成固定大小的块。
- 这些块按照一定的规则,如轮流或按块交替,分配到不同的物理磁盘驱动器上。
- 每个磁盘驱动器只存储一部分数据,因此所有磁盘驱动器都可以同时读写数据,从而提高了读写速度。
- 当需要读取数据时,RAID控制器会从所有驱动器中读取数据块,然后将它们组合成完整的数据块,并将其发送给请求数据的主机。
需要注意的是,RAID0没有冗余性,因此如果其中一个磁盘驱动器故障,整个系统将无法访问存储在该磁盘驱动器上的所有数据。因此,在使用RAID0时,应该备份重要的数据以防止数据丢失。
基于 Zones 的 RAID0,实际上就是将不同 Device 上的多个 Zones 当作一个 Device 上的来处理,并且尽量均衡分配读写负载。具体到两种 Zone 类型 seq/conv,要分别把设备上的两种 Zone 作为两类处理。
对 conv 类型,可以按照传统的 RAID0 逻辑处理,按相同大小的小块(条带)平均写入到不同设备上的 Zones 上即可。
对 seq 类型,则不能按照传统形式的 RAID0 逻辑来处理。如果分配了相同大小的条带,那么这些 Zones 的写指针就并不能抽象为逐个逐步写满的,而是同时写的,造成不能单独地对这些 Zones 进行 Reset 操作,并且需要特殊考虑这些 Zones 的占用大小。
要解决这问题,一种方案是修改 ZenFS 的 Zone Management 逻辑:
- 对一个 RAID 组内的 Zones,不能单独设置其中单独一个 Zone 的 Reset,只能对整个 RAID 组内所有 Zones 进行 Reset;
- 考虑 Zones 的已用容量的时候,只能考虑整个 RAID 的已用容量。
另一种方案是将一个 RAID 区域抽象为一个 Zone:
- 结构上,这个抽象的 RAID Zone 包含来自多个 Devices 的多个 Zones;
- 逻辑上,屏蔽了对实际 Zone 的 Reset 和求写指针操作,抽象为一个统一的 RAID Zone 的 Reset 和写指针操作;
- 会造成一些限制,例如显著增大了 Zone Size,再一次降低了 Zones 管理能力。
还有一种方案是让 ZenFS 支持不同大小的 Zones。
实现上可以先采用抽象为 RAID Zone 来实现 RAID0 的方案,之后再修改 ZenFS 的逻辑。
RAID1 逻辑
上文中谈论的 seq Zones 的限制,对其他大部分 RAID 类型同样成立,不过 RAID1 由于其 1:1 镜像的特殊性,可以做到更简单直接的抽象。具体而言,将 N 个 Device 上所有的 seq 同时映射到一个 RAID Zone,写的时候直接写 N 份,读的时候做一下读负载均衡。如此实现的话则不需要考虑 RAID 条带分割的问题。
RAID5 逻辑
动态 RAID 逻辑
为了实现动态的分块 RAID 逻辑分配,需要让 ZenFS 支持文件系统的动态扩容和缩容,同时需要找到存储 Zone - RAID 分配策略这一 map 数据的位置。
ZenFS 目前应该是不支持动态缩小容量的,当数据后端的 Zone 数量小于 Superblocks 中记录的值的时候,会拒绝挂载。但是如果 Zone 数量大于 Superblocks 中的记录,目前暂时没有找到类似的处理策略,可能能够用运行中修改 ZenFS::superblock_.nr_zones_ 的方法来扩容,但是结果未知,可能需要测试。如果需要动态缩小容量,可能需要使用 GC 逻辑。
存储额外的 RAID Zone 映射,可能需要使用 aux_path……
异步读写
目前使用io_uring异步读写多个device,以达到提高读写性能的目的。
liburing的使用:https://arthurchiao.art/blog/intro-to-io-uring-zh/#27-%E7%94%A8%E6%88%B7%E7%A9%BA%E9%97%B4%E5%BA%93-liburing
文件系统通用性
本方向将研究 ZenFS 以及其他通用的文件系统 在 ZNS 上的应用。
让 ZenFS 更加通用
减少对 RocksDB 的依赖
当前 ZenFS 对 RocksDB 有许多依赖,这与 ZenFS 设计时的目的有关。ZenFS 被设计为 RocksDB 的对 Zoned Block Device 上的文件管理系统,数据读写完全由 RocksDB 管理,数据结构、程序日志、文件系统接口、测试方法等都在 RocksDB 代码当中,并不是 ZenFS 的逻辑。ZenFS 完全作为 RocksDB 的一个插件存在,无法独立编译也无法直接运用在其他程序中,既不方便开发也不方便使用。
当前,为了减少对 RocksDB 的依赖,我们的解决方案是将 RocksDB 首先编译为静态代码库 librocksdb.a,然后将这个静态库和所有的头文件安装到系统的搜索路径中,从而让一个独立的 ZenFS 能够使用其中的头文件定义和静态代码。
这其中是有许多问题的,例如 RocksDB 利用 Configurable 的基类完成了基于字符串到对象的对象工厂,但是如果将其编译为 librocksdb.a,就无法对其他使用到这个 .a 文件的程序完成这个工厂的查找过程。
TODO: 解决方案。
文件通用性
当前 ZenFS 的文件存储逻辑为..... TODO
Record 在磁盘上的结构可以总结如下:
| 种类 | 长度 | 可能的作用 |
|---|---|---|
| header | zMetaHeaderSize==(sizeof(uint32_t) * 2) | 记录数据块大小和校验和的信息 |
| data | record_sz | 存储实际的记录数据 |
| 校验和 | sizeof(uint32_t) | 用于校验数据完整性的校验和 |
以下是 header 的结构总结:
| 字段名称 | 字段类型 | 描述 |
|---|---|---|
| record_crc | uint32_t | 记录的 CRC 校验和 |
| record_sz | uint32_t | 记录的大小(字节数) |
其中,header 保存了 record_sz 和 record_crc,record_sz 是 data 的长度,record_crc 是 data 的校验和。data 中存储了实际的记录数据。actual_crc 是根据 data 和 record_sz 计算出的校验和,与 record_crc 进行比较以确认数据完整性。
一个 ZoneFile 在存储介质上的结构:
| 种类 | 长度 | 作用 |
|---|---|---|
| 文件 ID (File ID) | 4 字节 | 用于唯一标识文件 |
| 文件大小 (File Size) | 8 字节 | 记录文件大小 |
| 寿命提示 (Write Lifetime Hint) | 4 字节 | 用于提示写入寿命 |
| 区间 (Extent) | 可变长度 | 记录文件的一个区间 |
| 修改时间 (Modification Time) | 8 字节 | 记录文件最近一次修改的时间戳 |
| 活动区间的开始 (Active Extent Start) | 8 字节 | 记录当前活动区间的开始位置 |
| 是否稀疏 (Is Sparse) | 1 字节 | 标记文件是否为稀疏文件 |
| 关联文件名 (Linked Filename) | 可变长度 | 记录与该文件有关联的其他文件名 |
数学分析和ML调参
对于zenfs运用数学分析和ML进行调参
方案一 基于方差的方法判定参数重要性
参考论文:Carver: Finding Important Parameters for Storage System Tuning
流程:
1. 首先根据PI系数计算出最重要的参数,PI系数根据方差给出定义:
$$ Var(S)=\frac{1}{|S|} \sum_{i=1}^{|S|}(y_i-μ)^2 $$
$$ PI(P)=Var(S)-\sum_{i=1}^N\frac{S_{P=P_i}}{S}Var(S_{P=p_i}) $$
这里PI系数越大,由于Var(S)是个常数,PI系数的后一项是当参数中的P取不同值时将S拆分成子集,获得这些子集的方差加权而成,如果后半部分越小,说明P这个参数的影响力越大,也就是说当PI系数大时,参数P是重要的参数。因此第一步选出这里最大的作为最重要的调参参数。
2. 再用固定之前选定参数的方式选择最重要参数,给出了条件参数重要性的公式如下所示:
$$ CPI(Q|P=p)=Var(S_{P=p})-\sum_{j=1}^m\frac{|S_{Q=w_j,P=p|}}{S_P=p}Var(S_{Q=q_j|P=p}) $$
对于所有P中的取值,选择其中最大的作为CPI指数: $$ CPI(Q|P)=\mathop{\max}_{i=1}^nCPI(Q|p=p_i) $$ 选择下一个最大值的参数作为次重要参数。
3. 停止条件
停止的方案有两种:
-
当选择的参数到了一定个数
-
CPI指数已经降低到一定阈值以下,说明剩余的参数对于目标而言影响不大
现存问题
- 确定调参的参数是哪些
- 数据集如何收集,论文中提到了数据集训练了4年,虽然拉丁超采样可以让我们只需要部分数据集,但是这仍然是个问题
- 如何测试调参的效果
融合文件系统
本方向将研究将 ZenFS 与其他支持 ZNS 的文件系统进行融合,从而扩展其灵活性并提升更多使用场景下的性能。
预期实现
当前 ZenFS 通过在超级块中记录 aux_path 来添加辅助文件系统,用于存储 Lock 文件和 Log(运行日志)文件。
如果能够同时管理 ZenFS 和辅助文件系统,可以让 ZNS 的应用场景更加广泛,也可以适当提高性能。
实现 Zone 的统一分配
在 Btrfs 和 f2fs 对 Zoned Namespace Devices 的适配中,有各自的 Zone 分配逻辑;而 ZenFS 也有自身的 Zone 分配逻辑。通过在 ZNS 上结合通用文件系统与 ZenFS,可以实现在同一个 ZNS 上两种文件系统的动态容量和负载分配。
例如,当文件系统检测到一个路径下有较大的随机写入时,可以将这个目录划分给 ZenFS 进行管理,一个统一的 Zone 管理器将一些 Zones 分配给 ZenFS。当 ZenFS 写入到一定数量的时候,可以向 Zones 的管理程序申请更多的 Zones 用于数据写入。同样的,当 ZenFS 完成垃圾回收,可以将部分空余 Zones 释放出来,并交还给 Zones 管理程序。
通过动态地分配 Zones,可以提高多文件系统融合情况下的空间利用情况,从而提高系统的灵活性。
为了实现 Zone 的统一分配,大致有两种实现方式:
-
通过 ZoneFS 和 POSIX 文件接口来管理 Zone 的分配。
此时,Zone 管理程序、ZenFS、辅助文件系统三者比较独立,Zone 的分配和归还可能需要使用 RPC 实现。
具体而言,需要在系统中首先启动一个 Zone 的管理程序作为 RPC 服务器,ZenFS 和 辅助文件系统在需要分配和归还 Zones 的时候通过 RPC 获取或者传递目标 Zone 的文件描述符。
-
将 ZenFS 独立实现一个 POSIX 接口,并将 Zone 分配逻辑、ZenFS、辅助文件系统一同编译,合成为一个独立的文件系统。
此时 ZenFS 类似于辅助文件系统的一个加速区域,能够更加智能自动地完成数据库等负载任务……吗
为了实现 Zone 的统一分配,需要修改辅助文件系统的分配逻辑。如果通过 ZoneFS 来支持,还需要其支持 ZoneFS 作为数据后端。
文件系统级「RAID」
有可能可以在 ZenFS、辅助文件系统中实现类似 RAID 的逻辑,通过文件或数据区块的冗余来提高容错。
文件系统级读写分离优化
ZenFS 适合于随机写入,但是不适合随机/顺序读取;辅助文件系统上随机写入性能不如 ZenFS,但是读性能往往高于 ZenFS。如果一个数据区域成为读写热点,那么可以在负载程度不高的情况下将数据拷贝一份到辅助文件系统,用于优化读性能。
整体架构
为了提高项目的整体性,需要一个整体的架构。
[toc]
┌─────────┐ ┌───────┐
│ RocksDB │ │ App │
└────────┬┘ └┬──────┘
FS/POSIX│ │VFS/FUSE
┌─AquaFS────┼───┼──────────┬──────┐
│ │ │ │Turner│
│ ┌─────┴───┴────────┐ ├──────┴─────┐
│ │ Data Router │ │Configurator│
│ └──┬──────────────┬┘ └──────┬─────┘
│ SST │ │ Data │
│ ┌──────┴───┐ inode ┌──┴───────┐ │
│ │ AquaZFS │◄──────┤ ExtFS │ │
│ └──┬───────┘ └───┬──────┘ │
│ │RAID Extent│ │
│ │ ┌───────────────┤Data │
│ ┌──┼───┼───────────────┼──────┐ │
│ │ │ │Zones Allocator│ │ │
│ ├──▼───▼───────────────▼──────┤ │
│ │ io_uring/xNVME │ │
│ ├──────────────┬──────────────┤ │
│ │ Seq Zones │ Conv Zones │ │
└─┴──────────────┴──────────────┴─┘
- App:文件系统请求负载
- RocksDB:数据库请求
- Data Router:
FileSystem请求路由器,需要判断当前请求是否适合 WAL 优化 - Turner:动态调整运行过程中的参数
- Configurator:静态调整文件系统参数,建立文件系统时给出建议参数
- AquaZFS:经过修改和优化的 ZenFS,支持 RAID 等功能
- ExtFS:有 inode 系统的运行于 Seq/Conv Zones 上的通用文件系统
- 对普通请求,直接使用 Conv Zones
- 对 AquaZFS 的新文件,提供 inode 索引等读写优化
- 对较大的冷数据文件,分配到 Seq Zones
- 将一些可以异地更新的数据以
AquaFS::Extent形式写入 AquaZFS
- Zones Allocator:为 AquaZFS、ExtFS 提供 Zone 分配服务
- Zones:
- Seq Zones:只能顺序写的 Zones
- Conv Zones:可以随机写的 Zones
- AquaFS:整体文件系统
细节
RocksDB 使用 AquaFS
RocksDB 使用 AquaFS,可以走两种数据通路:FileSystem 和 POSIX 接口。
RocksDB 使用 FileSystem 接口使用 AquaFS
将 AquaFS 编译为 RocksDB 插件,Data Router 使用 FileSystem 接口。
Data Router 主要转发 SST 请求到 AquaZFS,其他请求转发到 ExtFS,并对特殊情况做二者的负载均衡。
RocksDB 使用 POSIX 接口使用 AquaFS
AquaFS 的 Data Router 通过 Kernel Module 或 FUSE 提供 POSIX 访问接口,并智能判断数据负载位置。
App 使用 AquaFS
由于假定 App 并未实现 FileSystem 接口,所以 App 数据可以通过 Kernel Module / FUSE 方式经过 Data Router 到下层。
调参模块
AquaFS 中调参模块主要有两个部分:Configurator、Turner。
Configurator 在文件系统创建前评估当前系统更适合的固定参数,并结合需求给出合适的参数选择和预估的性能区间。
Turner 在文件系统使用过程中保持运行,根据系统当前状态动态调整可改变的参数,以获得更加灵活良好的整体表现。
可调参数
- 固定参数
- 块大小
- 固定 RAID 参数
- 数据后端类型
- GC
- GC 容量阈值
- GC 间隔时间
- 动态 RAID
- 分配时间(GC)
- 分配参数(0/1/5...)
- 文件请求分类
- 分类为 SST、普通数据
- 分类冷热文件/数据
- IO 加速方式:io_uring/xNVME
AquaZFS 和 ExtFS
ExtFS 是主要运行于 Conv Zones 上的针对 ZNS 优化的文件系统。主要特性:
- 必须原地更新的数据放在 Conv Zones 内,如 Superblock 等(?
- 适合异地更新的数据通过 AquaZFS 保存在 Seq Zones 内,如 MetaData(?
- 如果智能检测到 AuqaZFS 内部分数据不适合 Seq Zones 存储,则转发到 ExtFS 内处理
- 用冗余的 inode 等为 AquaZFS 提供索引,可以动态降低其内存消耗
AquaZFS 是基于 ZenFS 的优化修改,支持以上特性,在保存高性能的同时提升文件系统的灵活性。
RAID
在 AquaZFS 从写盘前到实际写盘之间,存在一层 RAID 逻辑。
- 可灵活配置为:静态固定参数 RAID、动态分区 RAID
- 可以在用户态驱动 NVME,或者内核态使用 liburing 进行 IO 加速,充分利用多盘优势提升性能
- 利用 Turner 提供的建议,在 AquaZFS 垃圾回收时或合并 Extent 时调整 RAID 逻辑,使文件系统在安全性、性能上有更好的权衡点
Zones Allocator
为 AquaZFS 和 ExtFS 提供统一的 Zones 分配服务。
- 让整盘空间得到更加充分的利用,减少由于分开两种子系统造成的空间碎片
- 根据历史数据,测算不同 Zones 的寿命和速度,来控制 Zones 的分配逻辑,延长磁盘寿命,提高磁盘吞吐
IO 加速
在 AquaFS 向上提供 FileSystem 接口时,由于负载程序对 FileSystem 接口做了适配,所以可以让负载程序和整个 AquaFS 都跑在用户态。
当 AquaFS 整个运行在用户态,可以使用 xNVME 用户态 NVME 协议驱动,降低内核态用户态切换的性能损失,同时也可用 io_uring 加速。
若 AquaFS 使用 POSIX 接口,可以使用 VFS 或者 FUSE 接口,此时也可以用 xNVME 或者 io_uring 进行 IO 加速。
智能化
这个架构的「智能」体现在哪?
- 相比与 ZenFS,灵活性更强
- 适配没有针对优化的工作负载,智能识别适合 WAL 的数据,用更合适的方式处理
- 可调整的静态、动态参数更多
- 提供 RAID 功能,并可以动态分配
- 数据安全性更强:RAID 功能
- 智能分配请求
- 在 Data Router 层合理分配 SST、普通数据请求
- 在当前请求不适合 AquaZFS 的时候将 ExtFS 作为后备
- 进行读写请求分离
初赛目标
RocksDB + FileSystem + Turner + AquaZFS + RAID
存储着进度报告的文件夹,你不知道它什么时候会更新。
RAID
-
完成了 ZenFS 上 RAID 的部分调用逻辑(未测试)
通过添加
fs_uri的解析格式完成,新的格式为:./db_bench --fs_uri=zenfs://raid1:dev:null0,zonefs:/mnt/zonefs代码修改于
zdb_zenfs.cc等。 -
实现了 RAID0、RAID1 的部分逻辑
见新增的
zone_raid.cczone_raid.h。
各个模块完成度
-
Data Router
- FUSE 测试
-
aquafs::FileSystem接口移植 -
aquafs::FileSystem和rocksdb::FileSystem之间的适配
-
调参
- 有一个可以运行的用于测试的 Demo
- 优化 Demo 为 Turner 以持续运行
-
AquaZFS
- 重写大部分模块,将主要逻辑脱离 RocksDB
- 与 RAID 模块适配并测试
-
ExtFS
- 测试 Conv Zones 兼容性
- 测试 MetaData 与 Extent
-
RAID
- RAID 数据逻辑
- RAID 分配逻辑与 GC
- Zones Allocator
TODO List
RAID
-
完善数据恢复逻辑
-
当读写发现读写错误,且出错分区可以被数据恢复,则立即开始恢复数据。
-
先写入一个大文件,然后软件上设置一个块为
Offline,然后在读取的过程中自动修复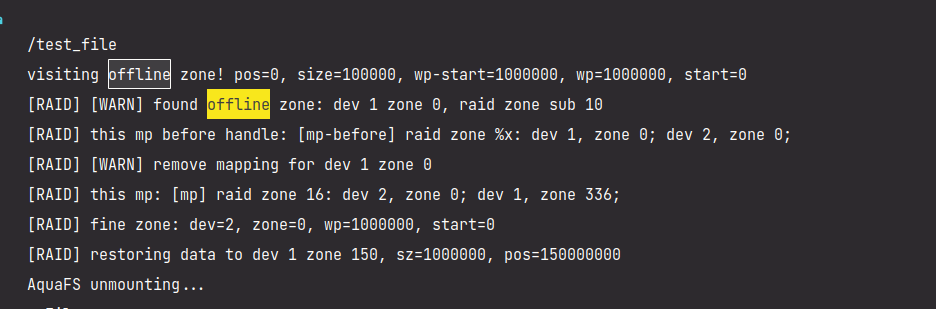
-
-
完善分区 RAID 自动映射逻辑
- 从命令行配置:如果访问到非映射区域则添加哪一种类型的 RAID 分区
- 持久化分区存储配置
-
添加
io_uring等异步优化-
liburing4cpp添加和测试 -
为全盘 RAID0 模式添加
io_uring- 将一个请求划分到不同设备和分区并进行分组和排序
- 将请求参数加入 RingBuf,有并行和串行逻辑
- 请求并等待请求结束
-
为分区 RAID0 添加
io_uring -
使用 C++20 的协程使
io_uring请求更加并行化
协程和
io_uring运行中的效果:
-
-
测试
-
可量化的 RAID 效果测试:
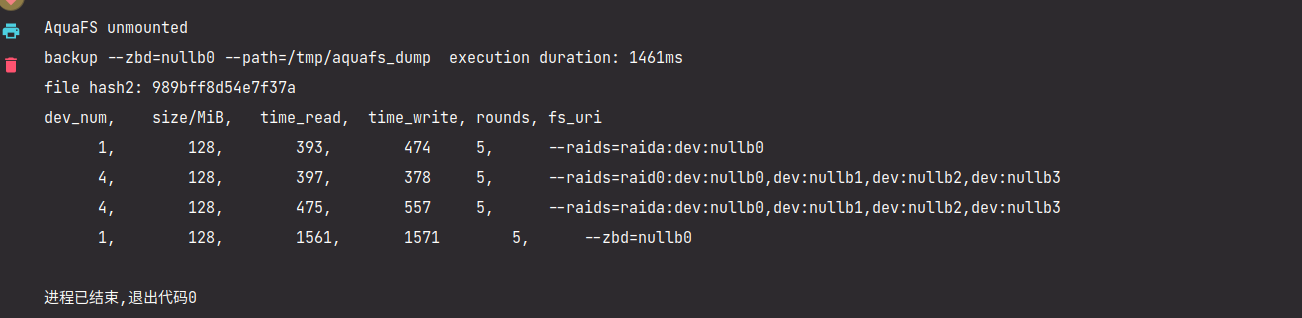
通过在读写函数中加上高精度延时模拟磁盘读写延迟,按照访问延迟和数据传输延迟延时,然后计量函数运行时间。
仍无法使用
nvmevirt等更合理的软件仿真方式。 -
程序性能测试
利用 perf 分析性能热点,效果为大都集中在 Kernel 内部的 IO 路径上
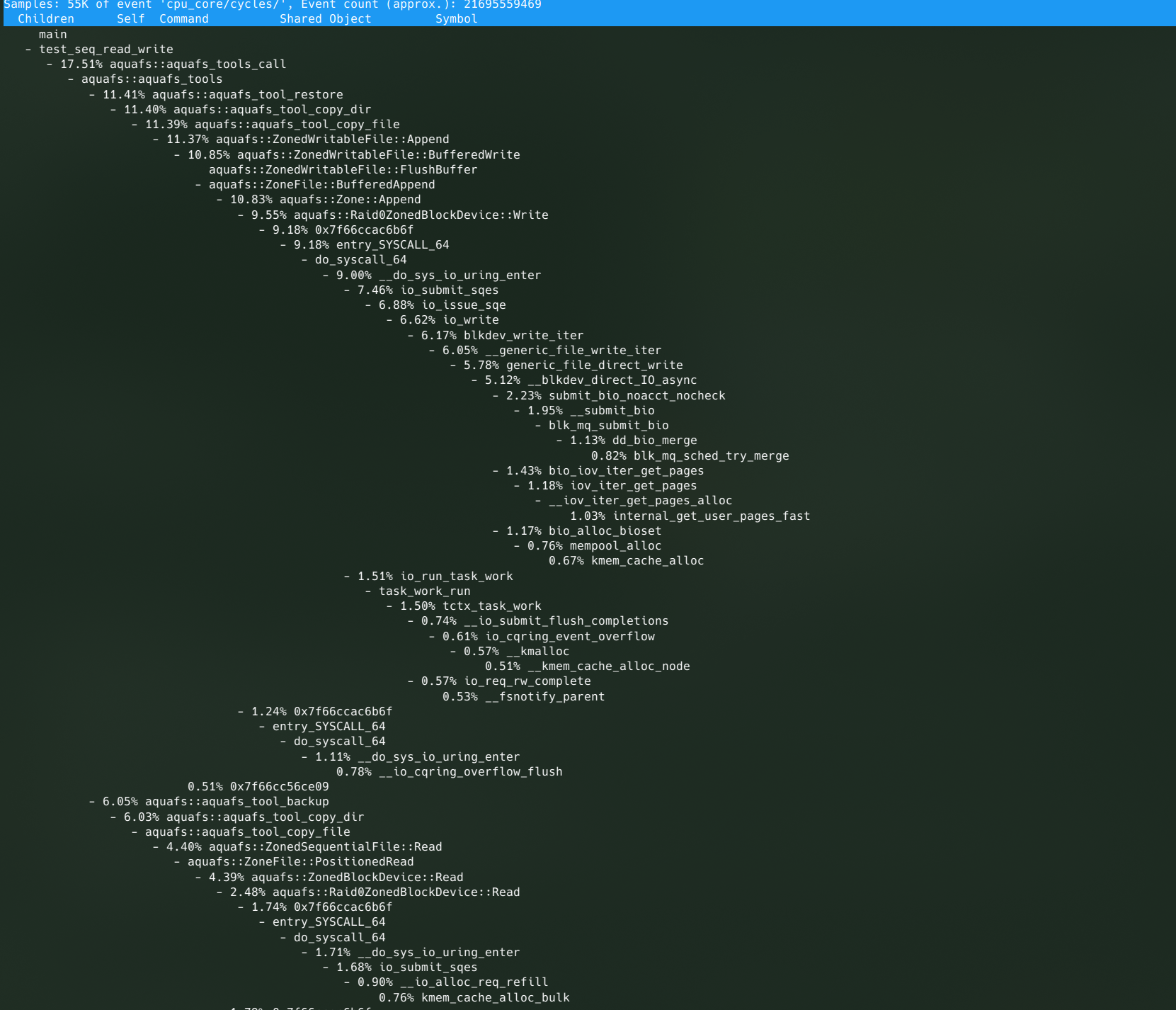
-
-
RAID5 逻辑
-
文档
- 摘要
- 概述
-
需求分析与调研
- 需求分析
- 往年队伍实现的分析
-
将原来调研的文档改改格式加进来
- Flash 调研
- ZenFS 调研
- 系统设计部分
-
系统实现部分
- 全盘 RAID 实现
- 分区 RAID 实现
- 分区 RAID 故障处理
- IO 加速
- 智能调参
- 总结和展望
- 参考文献
-
git 首页
- 添加测试效果图表
- 添加图表说明
-
完善一下在这里的摘要
- 创新点和特色(已经实现的和将要实现的)
- 完善一下主要工作和完成度、工作量
-
整理提交,将
submodule改成branch
-
图表
- 调参性能图表和说明
- Chiro
- 完善 FileSystem 接口然后把框架作为 RocksDB 插件跑起来
- 实现 Data Router
- 实现 FUSE 接口
- 将调参模块优化为守护进程
- 将分区 RAID 的分配逻辑与 GC 结合进行优化
- lyt
- 为 RAID 实现动态、静态 RAID5 逻辑
- 实现分区 RAID 的智能分配
-
进一步实现更多的调参目标
- RAID 参数的调参
- 动态分区 RAID 的智能分配
- GC 的调参
研究目标
初赛目标
总体:在几个方向有比较完善的可以以数值衡量的工作,并有一个可以通过 POSIX 接口调用的主要文件系统。
RAID
基于 Zones 的 RAID:
- 速度和磨损的负载均衡
- 数据区域损坏的检测与恢复
- RAID[0, 1, 5, 6, 10]
- 在多个层面实现 RAID,ZenFS 层和 ZBD 层
User Manual
……有用户吗?
Get Started
Build
Standalone Mode
这个模式用于尽量剥离 RocksDB 相关代码逻辑,加快编译调试速度
目前暂时不可用于读写性能测试。
Fixme:
- Zone close failed
- CURRENT file content error when using simple raid0
Plugin Mode
原 ZenFS 项目构建方式。
# 从我们 Fork 的项目 Clone,并且同时同步子项目
git clone https://github.com/RethinkFS/rocksdb -b aquafs --recursive
此时 plugin/zenfs 和 plugin/aquafs 被作为子项目的形式 checkout 到对应路径,二者是地位等同的 RocksDB 插件,通过 fs_uri 指定。
从命令行构建:
# 注意 Configurate 时候需要的参数
cmake -B build -S . -DROCKSDB_PLUGINS="AquaFS zenfs" -DWITH_SNAPPY=1 -DAQUAFS_EXPORT_PROMETHEUS=1 -DWITH_LIBURING=OFF
# 构建
cmake --build build
在 IDEA 中构建:
构建 db_bench 用于性能测试:
# 命令行构建,需要额外设置参数 DEBUG_LEVEL=0 以及 数据收集用 prometheus
cmake -B build -S . \
-DROCKSDB_PLUGINS="AquaFS zenfs" -DWITH_SNAPPY=1 -DAQUAFS_EXPORT_PROMETHEUS=1 -DWITH_LIBURING=OFF
# 构建
cmake --build build
# 创建两个 nullblk 设备:nullb0 nullb1
sudo ./plugin/aquafs/tests/nullblk/nullblk-zoned.sh 4096 32 0 64
sudo ./plugin/aquafs/tests/nullblk/nullblk-zoned.sh 4096 32 0 64
cd build
# 对单个设备测试
## 创建文件系统
mkdir -p /tmp/aquafs
sudo ./plugin/aquafs/aquafs mkfs --zbd nullb0 --aux-path /tmp/aquafs
## 跑分
sudo ./db_bench --fs_uri=aquafs://dev:nullb0 \
--benchmarks=fillrandom --use_direct_io_for_flush_and_compaction --use_stderr_info_logger
# 对两个设备的 RAID 测试
## 创建文件系统
mkdir -p /tmp/aquafs
sudo ./plugin/aquafs/aquafs mkfs --raids=raida:dev:nullb0,dev:nullb1 --aux-path /tmp/aquafs
## 跑分
sudo ./db_bench --fs_uri=aquafs://raida:dev:nullb0,dev:nullb1 \
--benchmarks=fillrandom --use_direct_io_for_flush_and_compaction --use_stderr_info_logger
或者在 IDEA 中添加 -DDEBUG_LEVEL=0 然后选择 db_bench 目标进行构建。
db_bench的一些有用的参数:
--fs_uri=aquafs://raida:dev:nullb0,dev:nullb1用于指定测试中的存储文件系统。
aquafs://则为使用我们修改后的文件系统,zenfs://则为原文件系统。
--benchmarks=fillrandom选择需要运行的测试。可用的测试:
"fillseq," "fillseqdeterministic," "fillsync," "fillrandom," "filluniquerandomdeterministic," "overwrite," "readrandom," "newiterator," "newiteratorwhilewriting," "seekrandom," "seekrandomwhilewriting," "seekrandomwhilemerging," "readseq," "readreverse," "compact," "compactall," "flush," "compact0," "compact1," "waitforcompaction," "multireadrandom," "mixgraph," "readseq," "readtorowcache," "readtocache," "readreverse," "readwhilewriting," "readwhilemerging," "readwhilescanning," "readrandomwriterandom," "updaterandom," "xorupdaterandom," "approximatesizerandom," "randomwithverify," "fill100K," "crc32c," "xxhash," "xxhash64," "xxh3," "compress," "uncompress," "acquireload," "fillseekseq," "randomtransaction," "randomreplacekeys," "timeseries," "getmergeoperands,", "readrandomoperands," "backup," "restore"
--use_direct_io_for_flush_and_compaction当使用 DirectIO 的时候,数据请求将不会经过 Kernel,而是直接访问设备,能够有效降低访问延迟,提高带宽。
--use_stderr_info_logger将
stderr作为logger的输出。
Source
项目组织方式为多层 git submodule,当编辑内层 submodule 内容时如果需要同步 submodule 状态需要逐层向上提交。
构建
本项目使用 CMake 作为项目构建工具。
CMake 使用步骤
项目中 CMake 工具主要有两个使用阶段:
- CMake Configuration:生成项目构建脚本。此阶段需要添加 CMake Configurate 参数。
- CMake Build:编译生成项目目标文件。
CMake Configurate 参数
ROCKSDB_PLUGINS:字符串,以空格分隔的插件列表。可用的插件:zenfs:原版 ZenFSaquafs:初赛版本 AquaFS,小写AquaFS:之后开发版本 AquaFS- 举例:
ROCKSDB_PLUGINS="zenfs aquafs"加载原版和初赛版本 AquaFS 作为插件ROCKSDB_PLUGINS="zenfs AquaFS"加载原版和之后开发版本 AquaFS 作为插件
AQUAFS_EXPORT_PROMETHEUS:是否开启 Prometheus 数据采集。AQUAFS_EXPORT_PROMETHEUS=1WITH_LIBURING:RocksDB 的PosixFilesystem是否开启 io-uring 加速。与 AquaFS 冲突,务必关闭。WITH_LIBURING=OFFWITH_SNAPPY:使用 libsnappy 压缩 SST,需要开启。
如果需要使用之后开发版本的 AquaFS,使用的参数为:
-DROCKSDB_PLUGINS="AquaFS zenfs" -DWITH_SNAPPY=1 -DAQUAFS_EXPORT_PROMETHEUS=1 -DWITH_LIBURING=OFF
如果需要使用初赛版本 AquaFS,使用参数为:
-DROCKSDB_PLUGINS="aquafs zenfs" -DWITH_SNAPPY=1 -DAQUAFS_EXPORT_PROMETHEUS=1 -DWITH_LIBURING=OFF
CMake Configurate
命令行方式
# 运行目录:rocksdb
# cmake -B build -S . <CMake Configurate 参数>
# for newer version
cmake -B build -S . -DROCKSDB_PLUGINS="AquaFS zenfs" -DWITH_SNAPPY=1 -DAQUAFS_EXPORT_PROMETHEUS=1 -DWITH_LIBURING=OFF
# for old version
cmake -B build -S . -DROCKSDB_PLUGINS="aquafs zenfs" -DWITH_SNAPPY=1 -DAQUAFS_EXPORT_PROMETHEUS=1 -DWITH_LIBURING=OFF
VsCode CMake 插件方式
见 JSON 文件。TBD。
CMake Build
命令行
# 运行目录:rocksdb
cmake --build build
VsCode CMake 插件方式
TBD。